
Copyright © 2020 Powered by MWeb, Theme used GitHub CSS.
与AOV网相对应的是AOE网,即边表示活动的网。AOE网是一个带权的有向无环图,其中,定点表示事件,弧表示活动,权表示活动持续的时间。通常,AOE网可以用来估算工程的完成时间。
设一个工程有11项活动,9个事件,事件 V1表示整个工程开始,事件V9——表示整个工程结束,问题:

我们可以说,我们可以对一个工程计划,先从头开始保证每个任务尽快完成,那么就可以计算出每个点的最短完成时间。
如果我们从尾开始,以尾的最快完成时间为期限,再逆推每个点最迟完成时间且保证不耽误尾节点的完成,那么就可以计算出每个点的最晚完成时间。
那么一个节点完成时间是在最早完成时间到最晚完成时间的区间内则不会影响整个工程的进度,如果一个节点最早完成时间和最晚完成时间相同,就意味着,如果这个节点延误了,整个工程将被延误。那么,这就是关键活动。
换句话,如果找到关键活动,如果加快关键活动的完成,整个工程将更快完成。
Ve(j):表示事件Vj的最早发生时间。
Vl(j):表示事件Vj的最迟发生时间。
e(i):表示活动ai的最早开始时间。
l(i):表示活动ai的最迟开始时间。
l(i)-e(i):表示完成活动ai的时间余量。
若时间余量为0,则该活动为关键活动,所在的路径为关键路径。
设活动ai用弧表示,其持续时间记为:dut() 则有:
求Ve(j)和Vl(j)需分两步进行:
这样,就能找到每个关键活动。
因此,可以提炼算法:
伪代码:
Status TopologicalOrder(ALGraph G, Stack &T) {
// 有向网G采用邻接表存储结构,求各顶点事件的最早发生时间ve(全局变量)。
// T为拓扑序列定点栈,S为零入度顶点栈。
// 若G无回路,则用栈T返回G的一个拓扑序列,且函数值为OK,否则为ERROR。
Stack S;int count=0,k;
char indegree[40];
ArcNode *p;
InitStack(S);
FindInDegree(G, indegree); // 对各顶点求入度indegree[0..vernum-1]
for (int j=0; jnextarc) {
k = p->adjvex; // 对j号顶点的每个邻接点的入度减1
if (--indegree[k] == 0) Push(S, k); // 若入度减为0,则入栈
if (ve[j]+p->info > ve[k]) ve[k] = ve[j]+p->info;
}//for *(p->info)=dut()
}//while
if (countnextarc) {
k=p->adjvex; dut=p->info; //dut
if (vl[k]-dut nextarc) {
k=p->adjvex;dut=p->info;
ee = ve[j]; el = vl[k]-dut;
tag = (ee==el) ? '*' : ' ';
printf(j, k, dut, ee, el, tag); // 输出关键活动
}
return OK;
} // CriticalPath
拓扑排序,简单地说,由某个集合上的一个偏序得到该集合上的一个全序,这个操作称之为拓扑排序。
偏序形式定义: 设R是集合A上的一个二元关系,若R满足: Ⅰ 自反性:对任意x∈A,有xRx; Ⅱ 反对称性(即反对称关系):对任意x,y∈A,若xRy,且yRx,则x=y; Ⅲ 传递性:对任意x, y,z∈A,若xRy,且yRz,则xRz。[1] 则称R为A上的偏序关系,通常记作≼。注意这里的≼不必是指一般意义上的“小于或等于”。 若然有x≼y,我们也说x排在y前面(x precedes y)。——摘自百度百科 全序形式定义: 设集合X上有一全序关系,如果我们把这种关系用 ≤ 表述,则下列陈述对于 X 中的所有 a, b 和 c 成立: 如果 a ≤ b 且 b ≤ a 则 a = b (反对称性) 如果 a ≤ b 且 b ≤ c 则 a ≤ c (传递性) a ≤ b 或 b ≤ a (完全性) 配对了在其上相关的全序的集合叫做全序集合(totally ordered set)、线序集合(linearly ordered set)、简单序集合(simply ordered set)或链(chain)。链还常用来描述某个偏序的全序子集,比如在佐恩引理中。 关系的完全性可以如下这样描述:对于集合中的任何一对元素,在这个关系下都是相互可比较的。 注意完全性条件蕴涵了自反性,也就是说,a ≤ a。因此全序也是偏序(自反的、反对称的和传递的二元关系)。全序也可以定义为“全部”的偏序,就是满足“完全性”条件的偏序。 可作为选择的,可以定义全序集合为特殊种类的格,它对于集合中的所有 a, b 有如下性质: 我们规定 a ≤ b 当且仅当。可以证明全序集合是分配格。 全序集合形成了偏序集合的范畴的全子范畴,通过是关于这些次序的映射的态射,比如,映射 f 使得"如果 a ≤ b 则 f(a) ≤ f(b)"。 在两个全序集合间的关于两个次序的双射是在这个范畴内的同构。——摘自百度百科
一个表示偏序的有向图可用来拜师一个流程图。它或者是一个施工流程图,或者是一个产品生产的流程图,再或是一个数据流图(每个顶点表示一个过程)。图中每一条有向边表示两个子工程之间的次序关系(领先关系)。
如果发现无前驱的顶点,可以说明图中存在环。 伪代码实现:
Status TopologicalSort(ALGraph G) {
// 有向图G采用邻接表存储结构。
// 若G无回路,则输出G的顶点的一个拓扑序列并返回OK,否则ERROR。
SqStack S;
int count,k,i;
ArcNode *p;
char indegree[MAX_VERTEX_NUM];
FindInDegree(G, indegree); // 对各顶点求入度indegree[0..vernum-1]
InitStack(S);
for (i=0; i<G.vexnum; ++i) // 建零入度顶点栈S
if (!indegree[i]) Push(S, i); // 入度为0者进栈
count = 0; // 对输出顶点计数
while (!StackEmpty(S)) {
Pop(S, i);
printf(i, G.vertices[i].data); ++count; // 输出i号顶点并计数
for (p=G.vertices[i].firstarc; p; p=p->nextarc) {
k = p->adjvex; // 对i号顶点的每个邻接点的入度减1
if (!(--indegree[k])) Push(S, k); // 若入度减为0,则入栈
}
}
if (count<G.vexnum) return ERROR; // 该有向图有回路
else return OK;
} // TopologicalSort
在对无向图进行遍历时,对于连通图,仅需从图中任一顶点出发,进行深度优先搜索或广度优先收缩,便可访问到图中所有顶点。对非连通图,则需从多个顶点出发进行搜索,而每一次从一个新的起始点出发进行搜索过程中得到的顶点访问序列恰为其各个连通分量中的顶点集。这些顶点集加上边就是联通分量
用DFS或BFS将一个图连接成一个生成树,DFS生成的是深度优先生成树,BFS生成的是广度优先生成树。
对于非连通图,每个连通分量中的顶点集,和遍历时走过的边一起构成若干棵生成树,这些连通分量的生成树组成非连通图的生成森林。
void DFSForest(Graph G, CSTree &T) {
// 建立无向图G的深度优先生成森林的(最左)孩子(右)兄弟链表T
int v; int j=0;
CSTree p,q;
T = NULL;
for (v=0; v<G.vexnum; ++v) visited[v] = FALSE;
for (v=0; v<G.vexnum; ++v)
if (!visited[v]) { // 第v顶点为新的生成树的根结点
p= (CSTree)malloc(sizeof(CSNode)); // 分配根结点
p->data=GetVex(G,v); // 给该结点赋值
p->firstchild=NULL;
p->nextsibling=NULL;
if (!T) T = p; // 是第一棵生成树的根(T的根)
else q->nextsibling = p; // 其它生成树的根(前一棵的根的“兄弟”)
q = p; // q指示当前生成树的根
DFSTree(G, v,p); // 建立以p为根的生成树
}//if
} // DFSForest
void DFSTree(Graph G, int v, CSTree &T) {
// 从第v个顶点出发深度优先遍历图G,建立以T为根的生成树
int w;
CSTree p,q;
bool first =TRUE;
visited[v] = TRUE;
for (w=FirstAdjVex(G, v); w!=-1; w=NextAdjVex(G, v, w))
if (!visited[w]) {
p = (CSTree) malloc (sizeof (CSNode)); // 分配孩子结点
p->data = GetVex(G,w);
p->firstchild=NULL;
p->nextsibling=NULL;
if (first) { // w是v的第一个未被访问的邻接顶点
T->firstchild = p; first = FALSE; // 是根的左孩子结点
} else { // w是v的其它未被访问的邻接顶点
q->nextsibling = p; // 是上一邻接顶点的右兄弟结点
}
q = p;
DFSTree(G,w,q) ;
}//if
} // DFSTree
深度优先搜索是求有向图的强连通分量的一个新的有效方法。
也就是说,在DFS之后,按照最后一个遍历到第一个遍历的点再来一次逆向DFS,如果可以遍历到所有点(除了向前推进删掉的点),那么就确定了一条强连通分量
最小生成树就是构造连通网的最小代价生成树。
因为最小生成树是要把所有的点连接起来,那么我们假设一个集合,这个集合存储已经被连接起来的点,我们就可以建一个数组,存储这个集合到任意未被连接的点的距离。
当我们每更新(加进一个点)的时候,就更新这个数组。
因此,prim就是一个贪心的思想,他首先取任意一个点作起点,然后生成这个起点到其他点的距离。如果这个点没有和其他点直接连接就假设为无穷大。
因为这个点终结是要纳入生成树的,那么就取最小的那个路,然后把与之相连的点纳入生成树集合,然后根据这个点更新距离数组(找与这个新入的点直接相连的)。
伪代码:
void MiniSpanTree_PRIM(MGraph G, VertexType u) {
// 用普里姆算法从第u个顶点出发构造网G的最小生成树T,输出T的各条边。
// 记录从顶点集U到V-U的代价最小的边的辅助数组定义:
// struct {
// VertexType adjvex;
// VRType lowcost;
// } closedge[MAX_VERTEX_NUM];
int i,j,k;
k = LocateVex ( G, u );
for ( j=0; j<G.vexnum; ++j ) { // 辅助数组初始化
if (j!=k)
{ closedge[j].adjvex=u; closedge[j].lowcost=G.arcs[k][j].adj; }
}
closedge[k].lowcost = 0; // 初始,U={u}
for (i=1; i<G.vexnum; ++i) { // 选择其余G.vexnum-1个顶点
k = minimum(closedge); // 求出T的下一个结点:第k顶点
// 此时closedge[k].lowcost =
// MIN{ closedge[vi].lowcost | closedge[vi].lowcost>0, vi∈V-U }
printf(closedge[k].adjvex, G.vexs[k]); // 输出生成树的边
closedge[k].lowcost = 0; // 第k顶点并入U集
for (j=0; j<G.vexnum; ++j)
if (G.arcs[k][j].adj < closedge[j].lowcost) {
// 新顶点并入U后重新选择最小边
// closedge[j] = { G.vexs[k], G.arcs[k][j].adj };
closedge[j].adjvex=G.vexs[k];
closedge[j].lowcost=G.arcs[k][j].adj;
}
}
} // MiniSpanTree
C语言实现:
它的本质就是贪心,先从任意一个点开始,找到最短边,然后不断更新更新len数组,然后再选取最短边并标记经过的点,直到所有的点被标记,或者说已经选好了n-1条边。
#include <stdio.h>
#include <string.h>
#define INF 1000000
//最小生成树
//普里姆
int G[200][200];
int len[200];
bool vis[200];
int prm (int n)
{
int i,k,ans = 0;
memset (vis,0,sizeof(vis));
for (i = 2;i <= n;i++)//初始化
len[i] = G[1][i];
vis[1] = 1;
for (i = 1;i < n;i++) //循环n - 1次
{ //因为n个顶点的MST一定是n-1条边
int imin = INF,xb;
for (k = 1;k <= n;k++)
if (!vis[k] && imin > len[k])
{
imin = len[k];
xb = k;
}
if (imin == INF) //没有找到最小值,说明图不连通
return -1;
vis[xb] = 1;
ans += imin;
for (k = 1;k <= n;k++)
if (!vis[k] && len[k] > G[xb][k])
len[k] = G[xb][k];
}
return ans;
}
int main()
{
int n,m;
while (~scanf ("%d%d",&n,&m))
{
int i,k;
for (i = 1;i <= n;i++)
for (k = 1;k <= n;k++)
if (i != k)
G[i][k] = INF;
else
G[i][k] = 0;
for (i = 0;i < m;i++)
{
int a,b,c;
scanf ("%d%d%d",&a,&b,&c);
if (G[a][b] > c) //如果有边多次录入,选权最小的那个
G[a][b] = G[b][a] = c;
}
int ans = prm(n);
printf ("%dn",ans);
}
return 0;
}
一个排序一个并查集只是表面,实质还是贪心,只不过普里斯是任选一个点选最短路径,而克鲁斯卡尔是看全局,全体边排序。
我们贪心选择最短的路径,而且保证每加入一个新的路径就要有一个新的顶点加入生成树。
C语言实现:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#define INF 1000000
//最小生成树
//克鲁斯卡尔
int vis[200];
struct eg
{
int v,u,w;
}e[100000];
int cmp (const void *a,const void *b)
{
struct eg *ta = (struct eg *)a;
struct eg *tb = (struct eg *)b;
return ta->w - tb->w;
}
int fin (int a)
{
int r = a;
while (vis[r] != r)
r = vis[r];
int k;
while (vis[a] != a)
{
k = vis[a];
vis[a] = r;
a = vis[k];
}
return r;
}
int add (int a,int b)
{
vis[fin(a)] = fin (b);
return 0;
}
int kls(int n,int m)
{
int i;
int ans = 0;
for (i = 0;i <=n;i++)
vis[i] = i;
for (i = 0;i < m;i++)
{
if (fin(e[i].u) != fin(e[i].v))
{
add (e[i].u,e[i].v);
ans += e[i].w;
}
}
return ans;
}
int main()
{
int n,m;
while (~scanf ("%d%d",&n,&m))
{
int i,k;
for (i = 0;i < m;i++)
{
int a,b,c;
scanf ("%d%d%d",&a,&b,&c);
e[i].u = a;
e[i].v = b;
e[i].w = c;
}
qsort(e,m,sizeof(e[0]),cmp);
int ans = kls(n,m);
printf ("%dn",ans);
}
return 0;
}
假若在删去顶点v以及和v相关联的个边之后,将图的一个连通分量分割成两个或两个以上的连通分量,则称顶点v为该图 的一个关节点。一个没有关节点的连通图成为重连通图。
在重连通图上,任意一对顶点之间至少存在两条路径,则在删除某个顶点以及依附于该顶点的各边时也不破坏图的连通性。若在连通图上至少删除k个顶点才能破坏图的连通性,则称此图的连通度为k。
利用深度优先搜索便可求得图的关节点,并由此可判别图是否是重连通的。
友深度优先生成树可得出两类关节点的特性:
伪代码:
void FindArticul(ALGraph G) {
// 连通图G以邻接表作存储结构,查找并输出G上全部关节点。
// 全局量count对访问计数。
int v;
struct ArcNode *p;
visited[0] = 1; // 设定邻接表上0号顶点为生成树的根
for (int i=1; i<G.vexnum; ++i) visited[i] = 0; // 其余顶点尚未访问
p = G.vertices[0].firstarc;
if(p) {
v = p->adjvex;
DFSArticul(G, v); // 从第v顶点出发深度优先查找关节点。
if (count < G.vexnum) { // 生成树的根有至少两棵子树
printf (0, G.vertices[0].data); // 根是关节点,输出
while (p->nextarc) {
p = p->nextarc; v = p->adjvex;
if (visited[v]==0) DFSArticul(G, v);
}//while
}//if
}//if(p)
} // FindArticul
void DFSArticul(ALGraph G, int v0 ) {
// 从第v0个顶点出发深度优先遍历图G,查找并输出关节点
int min,w;
struct ArcNode *p;
visited[v0] = min = ++count; // v0是第count个访问的顶点
for (p=G.vertices[v0].firstarc; p!=NULL; p=p->nextarc) {
// 检查v0的每个邻接顶点
w = p->adjvex; // w为v0的邻接顶点
if (visited[w] == 0) { // w未曾被访问,是v0的孩子
DFSArticul(G, w); // 返回前求得low[w]
if (low[w] < min) min = low[w];
if (low[w] >= visited[v0])
printf(v0, G.vertices[v0].data); // 输出关节点
}
else if (visited[w] < min) min = visited[w];
// w已被访问,w是v0在生成树上的祖先
}//for
low[v0] = min;
} // DFSArticul
如果给你两个整型变量,然后交换两个整数,你有多少种方法?
最常用的方法,就像两个杯子之间倒换水一样,先找个中间变量,然后倒换。
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner s = new Scanner(System.in);
int num1 = s.nextInt(),num2 = s.nextInt();
int tmp = num1;
num1 = num2;
num2 = tmp;
System.out.println("num1 = " + num1 + 't' + "num2 = " + num2);
}
}
作差法的好处就是可以少开一个变量,但是要承担溢出的风险。
用杯子倒水已经不合适形容了,最方便的就是袋子中放西瓜。A袋子里有代号为a的西瓜,B袋子里有代号为b的西瓜,小笨球想让两个袋子的西瓜倒换,但是一次只能拿出一个西瓜(拿出来之后必须放在袋子里不能放在地上云云)。
那么就可以把a拿到B袋子中,然后B中就有ab两个西瓜。
再把B中的b放到A的袋子中,那么就倒换完毕。
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner s = new Scanner(System.in);
int num1 = s.nextInt(),num2 = s.nextInt();
num1 += num2;
num2 = num1 - num2;
num1 = num1 - num2;
System.out.println("num1 = " + num1 + 't' + "num2 = " + num2);
}
}
位处理法是最棒的方法,既不需要开辟新的空间,又不会承担溢出的风险,唯一的缺点就是:不好理解。
先说说位异或,对位进行处理,同假异真。
位异或可以使得两个2进制串合并压缩成1个2进制串,然后用其中任意一个便可以求得另一个。
话句话说:
(a ^ b) ^ a == b;
(a ^ b) ^ b == a;
所以,交换两个数的时候只需要:
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
Scanner s = new Scanner(System.in);
int num1 = s.nextInt(),num2 = s.nextInt();
num1 ^= num2;
num2 ^= num1;
num1 ^= num2;
System.out.println("num1 = " + num1 + 't' + "num2 = " + num2);
}
}
数据结构因为考试的原因,学习的进度已经远超总结的进度,现在倒也挺好,当自学完一段时间再写总结,总能把握一些东西,温习一些东西。
和树的遍历类似,我们也需要从图中的某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次。这个过程就叫做图的遍历。
图的遍历算法是求解图的连通性问题,拓扑排序和求关键路径等算法的基础。
深度优先搜索(DFS)遍历类似于树的先根遍历,是树的先根遍历的推广。
深度优先遍历图的方法是,从图中某顶点v出发:
(1)访问顶点v;
(2)依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
(3)若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
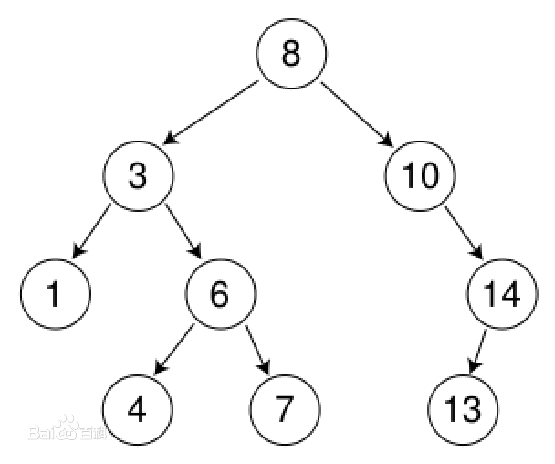
随便那个树做例子(在图中也是一样的),来演示DFS的过程:
首先以8作起点,8好节点入栈(并标记遍历过的节点),然后遍历3号节点,然后3号节点入栈
然后遍历1号节点,并标记。因为1号节点没有后继可以遍历,那么3号节点出栈,回到了了3号节点。
因为3号节点的后继1号节点已经被访问(被标记了),然后就寻找其他后继,发现还有6号节点没有标记(遍历),然后3号节点再次入栈,然后遍历6号节点,6号节点入栈。
6号遍历(标记之后),遍历4号节点,又遇到了没有后继的情况,那么4号节点遍历标记之后6号节点出栈,再次回到6号节点。
又发现6好节点的后继中有7号节点没有遍历,那么6号节点入栈,遍历7号节点。
7号节点没有后继,然后6号节点出栈,回到了3号节点。
3号节点没有可遍历后继,然后3号出栈,回到8号节点,然后发现8号节点有可遍历后继。
以此类推,直到所有节点都没有可遍历后继,那么DFS结束。
伪代码:
void DFSTraverse(Graph G, Status (*Visit)(int v)) {
// 对图G作深度优先遍历。
int v;
VisitFunc = Visit; // 使用全局变量VisitFunc,使DFS不必设函数指针参数
for (v=0; v<G.vexnum; ++v) visited[v] = false; // 访问标志数组初始化
for (v=0; v<G.vexnum; ++v)
if (!visited[v]) DFS(G, v); // 对尚未访问的顶点调用DFS
}
bool visited[MAX_VERTEX_NUM]; // 访问标志数组
Status (* VisitFunc)(int v); // 函数变量
void DFS(Graph G, int v) {
// 从第v个顶点出发递归地深度优先遍历图G。
int w;
visited[v] = true; VisitFunc(v); // 访问第v个顶点
for (w=FirstAdjVex(G, v); w!=-1; w=NextAdjVex(G, v, w))
if (!visited[w]) // 对v的尚未访问的邻接顶点w递归调用DFS
DFS(G, w);
}
遍历图的过程实质上是对每个顶点查找其邻接点的过程。其消耗的时间则取决于所采用的存储结构。当用二维数组表示灵界矩阵作图的存储结构时,查找每个顶点的邻接点所需时间为O(n^2),其中n为图中顶点的个数。而当以邻接表作图的存储结构时,找邻接点所需时间为O(e),其中e为无向图中边的数或有向图中弧的数。由此,当以邻接表作存储结构时,深度优先搜索遍历图的时间复杂度为O(n+e);
广度优先搜索(BFS)遍历类似于树的按层次遍历的过程。
自然界的BFS,感觉用这张图片描述算法极其形象!

和DFS相同,BFS也需要一个标记数组,但是不同的是DFS是用栈来实现而BFS是用队列实现。
BFS是树的层次遍历在图的应用,那么再用那个图演示一下BFS。
首先8号节点入队列,现在队列是【8】
然后从队列中拿出第一个元素,开始遍历,把8拿出来,现在队列为空
然后把8号节点标记,表示已经访问过,然后把8号节点所有后继3,10入队列,现在队列是【3,10】。
然后从队列中拿出第一个元素,开始遍历,把3拿出来,现在队列为【10】
然后把3号节点标记,表示已经访问过,然后把3号节点所有后继1,6入队列,现在队列是【10,1,6】。
然后从队列中拿出第一个元素,开始遍历,把10拿出来,现在队列为【1,6】
然后把10号节点标记,表示已经访问过,然后把10号节点所有后继14入队列,现在队列是【1,6,14】。
然后从队列中拿出第一个元素,开始遍历,把拿1出来,现在队列为【6,14】
然后把1号节点标记,表示已经访问过,1号节点没有后继然后不用让任何元素进队列,现在队列是【6,14】。
然后从队列中拿出第一个元素,开始遍历,把6拿出来,现在队列为【14】
然后把6号节点标记,表示已经访问过,然后把6号节点所有后继4,7入队列,现在队列是【14,4,7】。
然后从队列中拿出第一个元素,开始遍历,把14拿出来,现在队列为【4,7】
然后把14号节点标记,表示已经访问过,然后把14号节点所有后继13入队列,现在队列是【4,7,13】。
然后从队列中拿出第一个元素,开始遍历,把4拿出来,现在队列为【7,13】
然后把4号节点标记,表示已经访问过,4号节点没有后继然后不用让任何元素进队列,现在队列是【7,13】。
然后从队列中拿出第一个元素,开始遍历,把7拿出来,现在队列为【13】
然后把7号节点标记,表示已经访问过,7号节点没有后继然后不用让任何元素进队列,现在队列是【13】。
然后从队列中拿出第一个元素,开始遍历,把13拿出来,现在队列为空
然后把13号节点标记,表示已经访问过,13号节点没有后继然后不用让任何元素进队列,现在队列是空。
然后所有成员被访问,BFS结束。
更加上面很啰嗦的描述,我们能发现两点:
语言描述什么的不如代码来的直观:
void BFSTraverse(Graph G, Status (*Visit)(int v )) {
// 按广度优先非递归遍历图G。使用辅助队列Q和访问标志数组visited。
QElemType v,w;
queue Q;
QElemType u;
for (v=0; v=0; w=NextAdjVex(G, u, w))
if (!visited[w]) { // u的尚未访问的邻接顶点w入队列Q
visited[w] = TRUE; Visit(w);
EnQueue(Q, w);
}//if
}//while
}//if
} // BFSTraverse
因为遍历就是把图中的顶点依次访问,因此DFS和BFS时间复杂度相同,只不过是访问顺序不同罢了。(ps`:因为DFS用了递归,因此在实现上会慢于BFS,但是DFS的非递归方式将和BFS时间复杂度一样)。

Copyright © 2020 Powered by MWeb, Theme used GitHub CSS.