
午夜时分,电话响起,线上告急。你从千呼万钉中醒来,睡眼朦胧,手忙脚乱。
恍惚之间,终于梳理清楚发生了什么,一个陈年老应用突然停机,消息堆积,系统停摆。而你就像一个下水道小工疏通马桶一般,大力出奇迹,重启机器,恢复服务。只见消息队列中的堆积事件一泻千里,警告消除。
次日,你再也不想重现午夜凶铃,决定对系统进行永久性修复:加一个定时重启服务的脚本。
斗转星移,许多时日过去了,你也在不同的角落加了无数的脚本,也好久没有半夜惊醒,甚至还能悠闲享受下午茶。但是,直到今天。
今天,你们部门要降本增效,为了避免自己成为被砍掉的成本,你决定主动对线上的机器开刀:合并服务,裁撤机器。虽然你对机器上都部署了什么应用了然于胸,但是你已经不记得都有哪些脚手架支撑着应用的运转。
重建环境难如登天,你又开始难眠了。
变化的基础设施
复杂、神秘而神奇的线上环境承载了半部都市传说,甚至有些公司的线上环境本身就是一本需要口耳相传的上古神话。
我虽然没有看过沙漠下暴雨,但是看过没人说的清楚上面有什么的环境。我虽然没有看过大海亲吻鲨鱼,但是我看过重启再也起不来的机器。
如果你能说清楚任何一台机器上都部署了什么应用,以及机器上服务之间的依赖关系是什么样子的,你已经击败了八成的玩家。而造成这种局面的根本原因就是基础设施的易变。
- 新增一个服务时:“我找台机器部署一下”
- 某一个服务出问题时:“我上机器改一下”
- 需要对某个系统配置变更时:“我搞个脚本跑一跑”
看似常规运维变更,有文档记录或者没有文档记录,每一个环境都是如此的别致和独一无二,再加上人员变动,造就了无数的“祖传秘技”。
什么是不可变的基础设施
容器在被广泛接受的同时,「不可变」也逐渐被潜移默化的接受。
应用容器消亡之后,容器内的修改会随着容器一起不复存在,不要在容器内做修改就是最朴素的不可变理念。在程序启动阶段遇到问题,很少人还会把在容器内修修补补作为正经方案,而会回到最一开始的阶段,从容器构建阶段解决问题。
随之带来的就是大家对容器镜像无尽的信任感,容器突然出现问题?重建试试。换个机器跑不起来?肯定是机器的问题。
容器带来了什么
大家普遍认同 Docker 或者说容器引发了一场革命。但是为何说容器是一场革命,到底革了什么的命?
有一种说法是 Docker 简化了服务的管理,停启服务更加简单,但是事实上 systemd 或者 supervisor 等老牌服务管理、运维工具在这一点上不见得比 docker 难用多少。
我认为是镜像技术引爆了革命,一个不可临时修改的、固化的、自包含的交付物,真正的一次构建到处运行,一个可以快速铲掉和快速部署的实体,再也没有 「Works on my machine」,是如此的安心和可依赖。
也正是因为容器的重建是如此的快捷,使得我们有机会对「重启试试」发挥到极致,出问题了,重建容器看看?
你想尝试使用 Docker,但是你的业务如此复杂,上机器重建容器和直接上机器重启服务又有什么本质差别呢。
Pet vs Cattle
随之 Kubernetes 的到来,大规模的容器管理成为可能,而划定大规模容器的管理最佳实践也成为了热门议题。
如何饲养一只猫
如果你得到了一只猫,你会如何饲养它?我记得我在领回一只猫之后,花了很长的时间和脑细胞用来商定一个我和它都能接受的名字。
紧接着就是带着我的小猫去医院,制定疫苗计划,来保证我的小猫未来的健康。后面便是日复一日的铲屎和等着主子的眷顾。
小王子告诉我:正因为你为你的猫花费了时间,这才使你的猫如此重要。
经典的运维方式和猫的饲养是一样的,我们可以称之为宠物式运维。你会对机器和应用做详尽的规划,甚至为这个环境起一个名字,比如叫生产好了。
你也会对这个环境悉心照料,定期看看监控、做下升级保养。你为你的环境花费了时间,你的环境如此重要。
很难设想你的猫和你的环境突然间离你而去的场景,也许你会伤心的撕心裂肺和破产的撕心裂肺。
牧场主入门
在获得了一只猫之后,你一不留神又获得了一家牧场。但你可能无法像养一只猫一样养几千头牛,因为几千个名字应该是很难记住的。
你可能也不会依次带着你的牛去医院打疫苗,何不直接批发疫苗统一接种呢。如果有小牛犊存在严重的缺陷,也许你会陪在它身边悉心照料,但更可能的是把它尽早的从流程中剔除,省的浪费更多的饲料。
从此你的生活便目无全牛,只要为牛群建立足够多的保障设施,某一头牛的状态对整体又有什么影响呢。
放牧式运维
当你已经为上千头牛建设了完善的饲养设施,你会惊奇的发现,即使再加 100 头牛,并不会增加太多的成本。而不像饲养猫,当你有两只猫的时候,最好能有 3 个猫砂盆,否则你将有机会体验到鸡飞狗跳。
你决心当一个牧牛人运维,再也不想给生产环境的主子们铲屎了。拥抱 Kubernetes,像放牧一样管理你的应用。
牧养一群 Pod
你把生产环境的主子们装进集装箱,通过容器镜像对部署方式进行标准化,谁也甭想做非标的操作,再使用 Pod 对应用进行部署,再也不去关心应用在哪个 Node 上启动,这一切自有牧场(Kubernetes)自行处理。
一个 Pod 异常了?没关系,删掉看看,下次起来又是一个全新的应用。丝毫不会影响到牧场的正常运转。
一切丝般顺滑,岁月静好。
午夜时分,电话响起,线上告急。你从千呼万钉中醒来,睡眼朦胧,手忙脚乱。
恍惚之间,终于梳理清楚发生了什么,原来是不知何处流量涌现,节点雪崩。而你就像一个下水道小工疏通马桶一般,大力出奇迹,扩容机器,恢复服务。pending Pod 消失不见,警告消除。
次日,你再也不想重现午夜凶铃,但陷入深思,身为牧场主的你,逐渐意识到一个灯下黑的问题。
你可以轻松的同质化对待每一头牛,但你无法同质化整个牧场。
牧养真正的基础设施
几番梳理,你找到了问题的关键:尽管可以放牧式管理 Pod,但是机器的运维却还是宠物式的。
你依然会悉心照料每个机器:提前规划、取一个名字、单独控制规格、挑选操作系统,甚至还有几台深得你爱,嘘寒问暖,日夜牵挂,拥有单独的内部昵称代号。
作为业界领先的牧场主,你决心改造自己的牧场,如果能像管理 Pod 一样管理 Node 是不是一个好主意?
如果 Node 异常直接删除 Node,等着弹出新的?还没想完,你后背有些发凉,你还没有像信任容器一样信任虚机,虽然你深知重启可解决 90% 的故障,而重装系统可以解决 99% 的故障。
思来想去,你依然想做些尝试,稍加思考,锁定痛点有二:
- 机器按需快速弹缩,同质管理
- OS 镜像化:快速、安全、不可变
驯服虚机
经过调研,你发现事情并不像原来设想的那样深不可测,主流云厂商早就提供了野生工具,你只需要稍加驯服,便可以为自己的牧场服务。
AWS 很早便推出了 AutoScaling,可以按照负载和期望维护 EC2 的数目。而阿里云也有自己的实现(ESS),可以无需人工干预的根据规则对 ECS 进行扩缩容。
你看到了希望,这不就是 Node 的 Deployment 吗?但是只是扩容虚拟机对你来说并没有什么价值,你深知需要的是牛圈,而不是木材,你需要对他们进行驯服。
这时,你转头看到了你的 Kubernetes 集群,灵感蹦出,为何要直面虚拟机呢,只要新扩容出的机器能被纳管到集群中不就解决了基本问题。
说干就干,通过 AutoScaling 定义了启动命令,开机后进行标准化安装和执行 kube join 动作。当机器开机不久,就可以出现在 Kubernetes 集群中。你感觉距离目标进了一步。
驯服 OS
很快,你又发现了一个新的问题,传统的 OS 启动和容器实在无法比拟,明明所有的依赖都在容器内部,而且所有的应用都已经在容器内运行,但你还是不得不为 OS 内置的、没人使用的服务买单,这些服务拖慢了启动速度,还引入了安全漏洞。
而且,总是有人意识不到同质化管理的好处,时不时有人上机器做一些不可知的修改,导致你每次想释放虚机时需要去群里喊一喊,避免碰到什么神奇的 Bug。自寻烦恼,你苦笑道。
你打算驯服 OS,对传统的 OS 进行剪裁,除了容器依赖的东西全部清理掉,说不好能大大加快机器的启动速度。还有,最好能在啥地方加个告示,敬告大家不要在机器上做写操作,避免释放机器时文件的丢失。
有天,你发现了 AWS 的 bottlerocket 和阿里云的 ContainerOS,一个针对容器剪裁和优化的操作系统,你不需要亲自动手剪裁了,甚至都不再需要加一个告示,因为他们的 RootFS 都是只读的,连 SSH 都不会默认打开,从根本上杜绝了非标操作。

你尝试了一下,针对容器优化的 OS 启动贼快,点完弹出,一分钟后你就可以把业务调度上去了。把 Node 当做 Pod 管理,你看到了希望。
托管式放牧
但不久,你遇到了一个新的问题,创建机器一时爽,你的老板告诉你,你手里有一批机器存在一个要紧的 CVE 安全漏洞,需要抓紧时间搞一搞,你开始头大了,因为你知道,除了存量的节点,现在只要创建新的机器就有安全漏洞。
你有了一种若隐若现的感觉:你在走向深水区。
从放牧到自动放牧
一番探寻后,你看到了 Google 提出的 AutoPilot,也看到了阿里云 ACK 的托管节点池。节点的扩缩容、节点故障的自恢复、安全加固、OS 的托管,无不触动着你。你意识到应该从根本上解决问题:放手自建的 Kubernetes,全面拥抱托管。
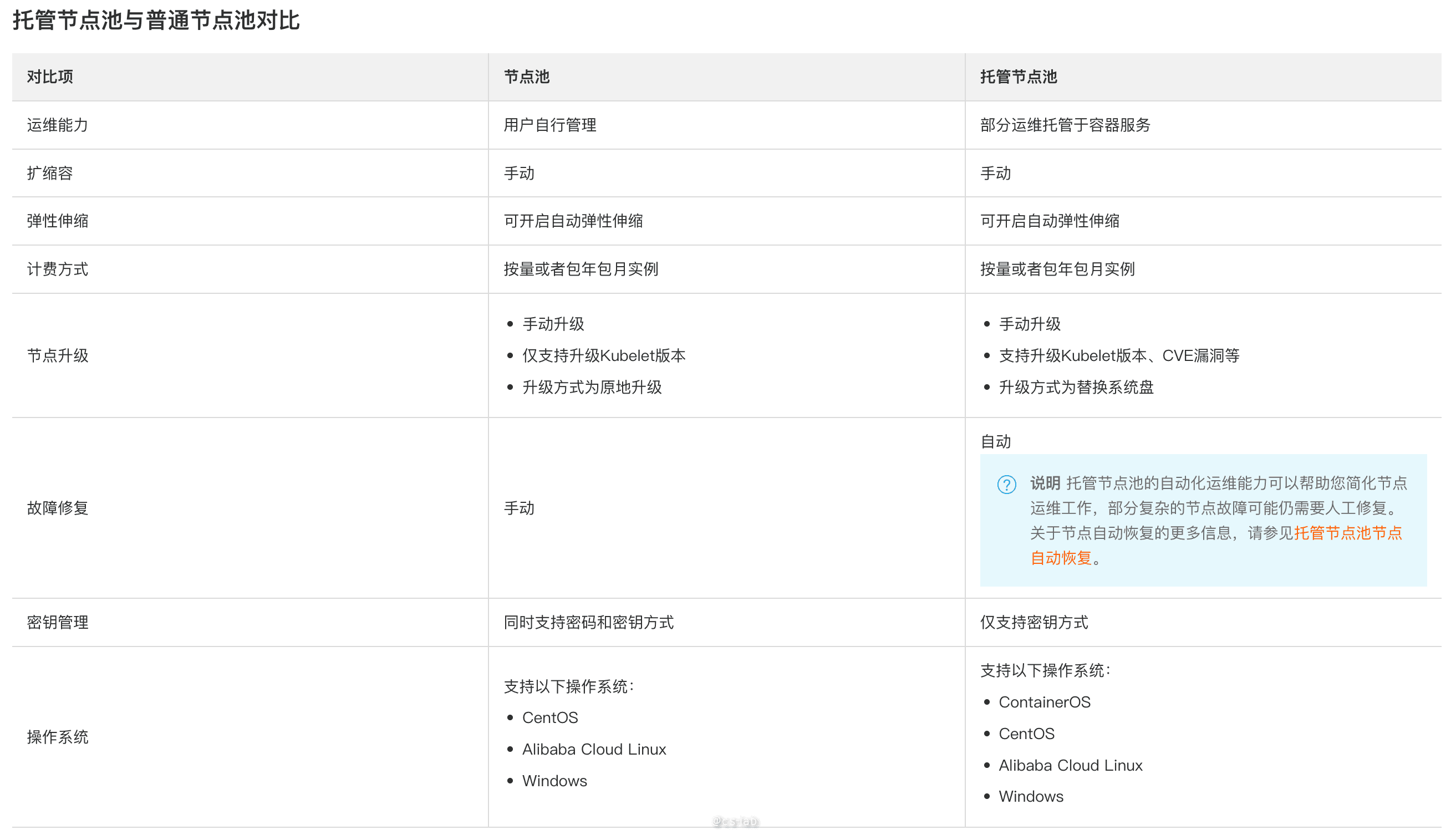
拥抱托管后,你豁然开朗,原来事情本应如此简单,多年的摸索仿佛一颗种子,在看到托管节点池后瞬间发芽成果。
从此,世界上又开始流传了新三板斧传统:等等自愈看看?Pod 删下看看?Node 删下看看?朴实无华且有效。


