
基数树(RadixTree),是一种比较有趣的数据结构,最近需要一种比较高效的查找,两度遇到了基数树,便整理下来给有相关需求的伙伴提供一种思路。
基本原理
对数据结构有些练习的小伙伴对字典树肯定不陌生,一句话解释基数树就是带压缩的字典树,从维基百科示例图中也可以明显看得这一点:
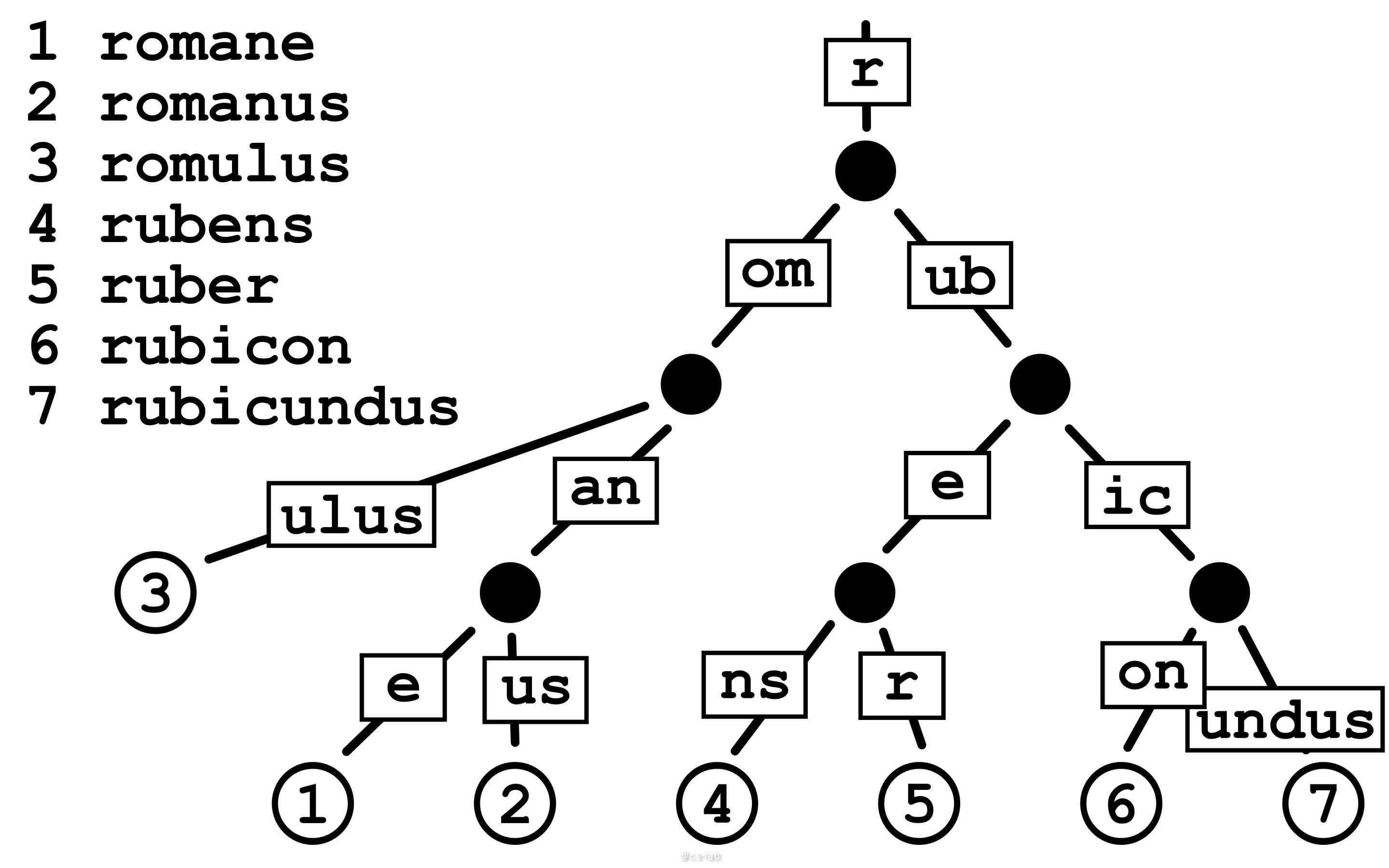
对于一般字典树(Trie),每条边是由一个字母组成,同样可以从维基百科中的示例图中看出字典树的一般规律:

因为基数树是对字典树的压缩,因此基本操作和字典树基本一致,只是多了节点的合并和分裂操作。下面我们就通过树的操作对比下基数树和字典树的不同。
新增值
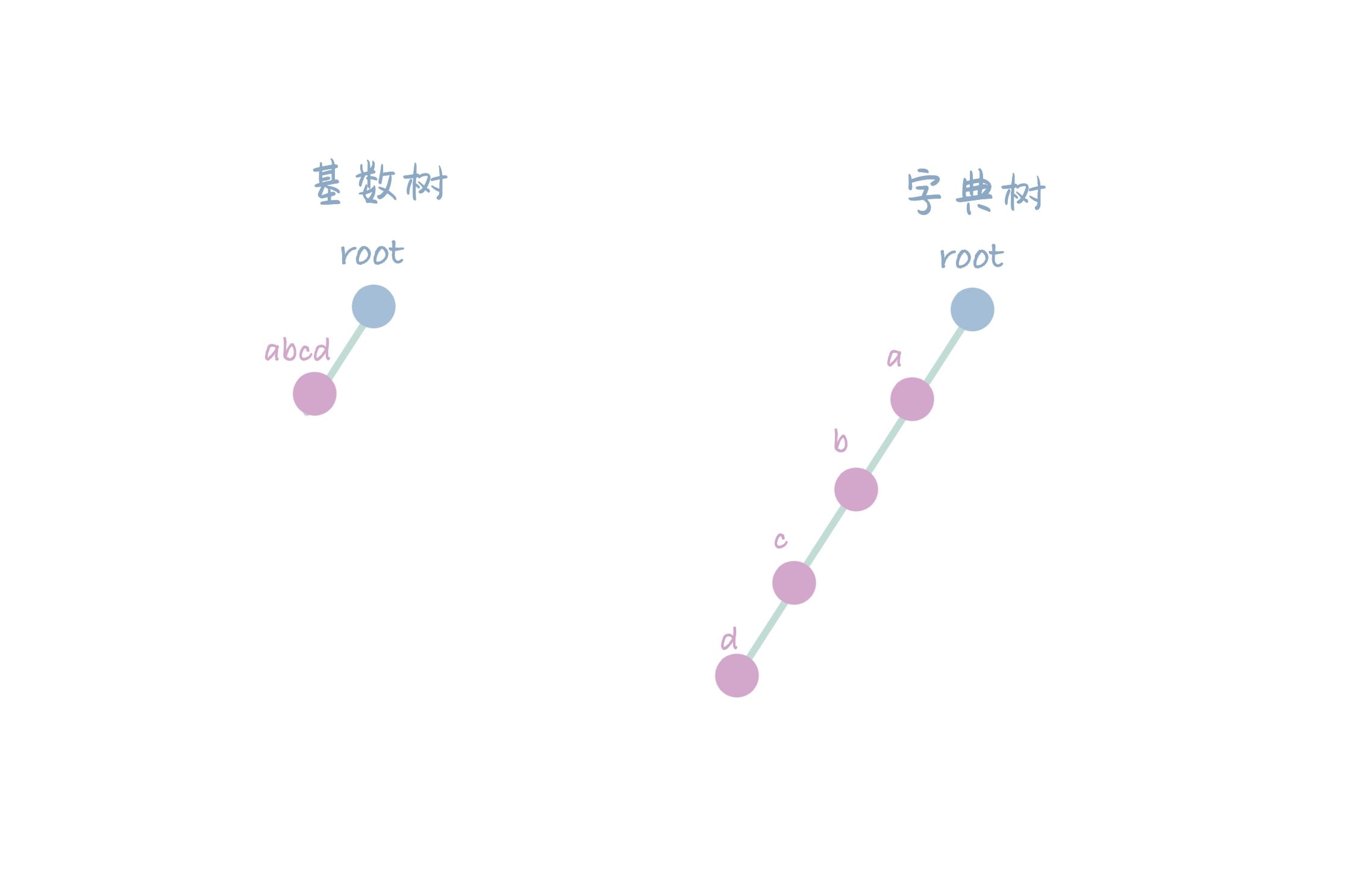
对于一颗空树的初始状态,基数树和字典树是一致的,只有 root 节点。

对基数树和字典树插入相同的字符串【abcd】,因为新子串无额外分叉,因此可以对子串压缩。
对基数树和字典树插入相同的字符串【abce】,当基数树的某一个节点需要分叉时,则对该节点进行分裂后再加入新节点。

对基数树和字典树插入相同的字符串【aecb】。

对基数树和字典树插入相同的字符串【aecd】。
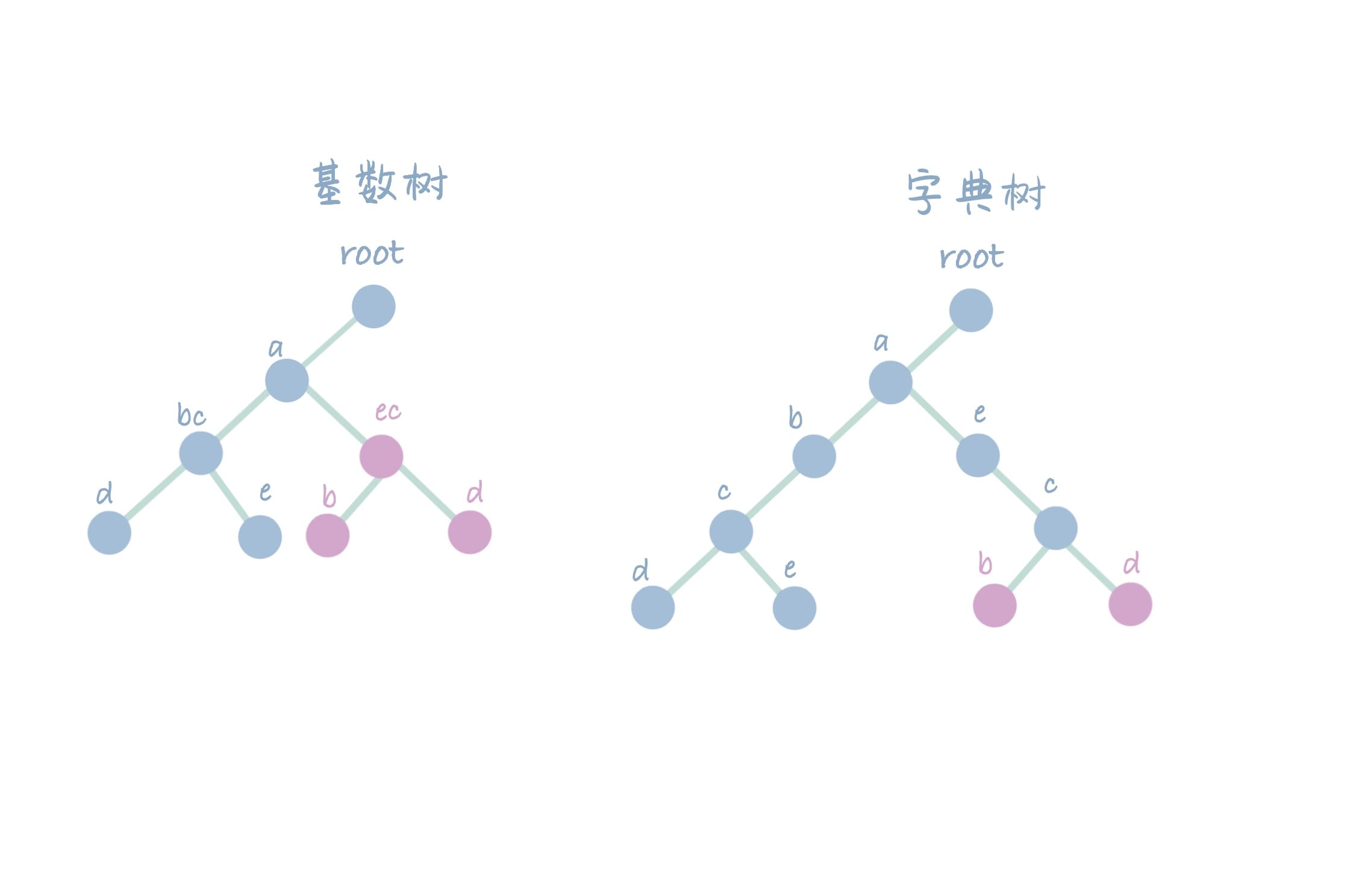
如上图的结果,基数树在这组 case 中,比字典树的深度少 1。以牺牲建树过程中的额外引入分裂操作,来优化查找时的效率。
删除值
基于上文中的树,对基数树和字典树删除相同的字符串【abcd】,可以看到因为节点(bc)的分叉消失,因此和子节点合并为(bce)。
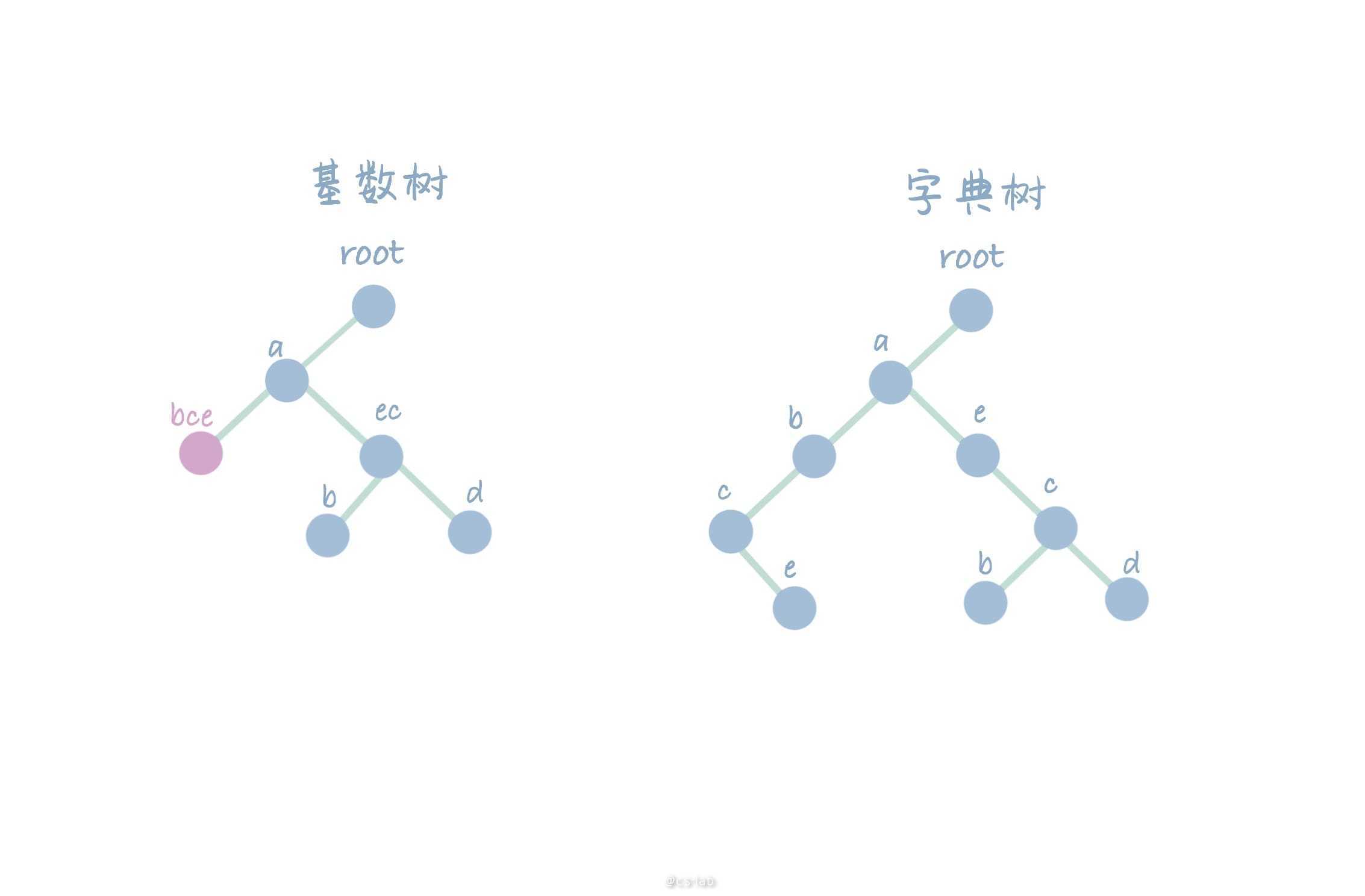
对基数树和字典树删除相同的字符串【abce】,同理,节点(a)和其子节点(ec)合并为(aec)。
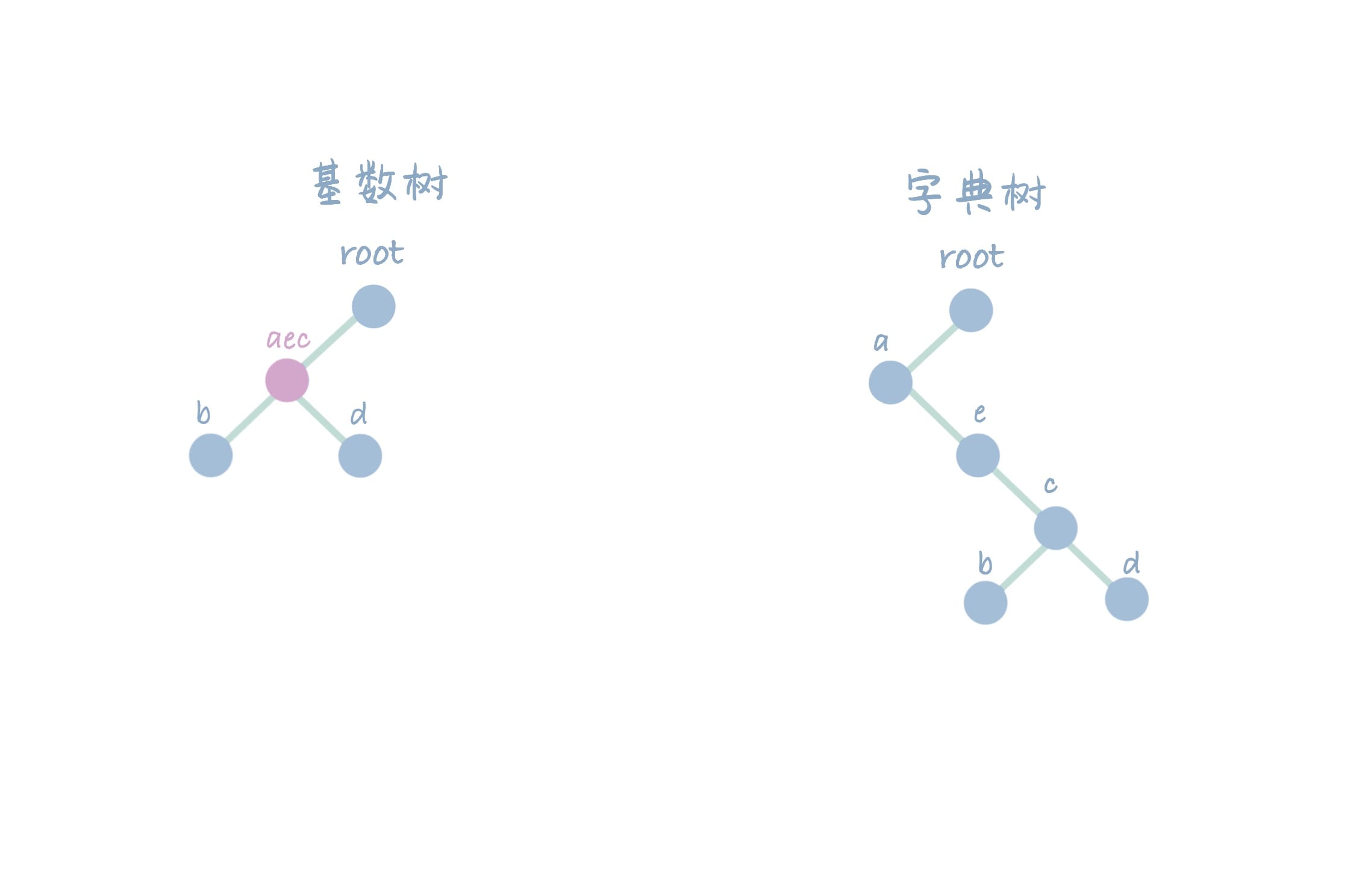
对基数树和字典树删除相同的字符串【aecb】。
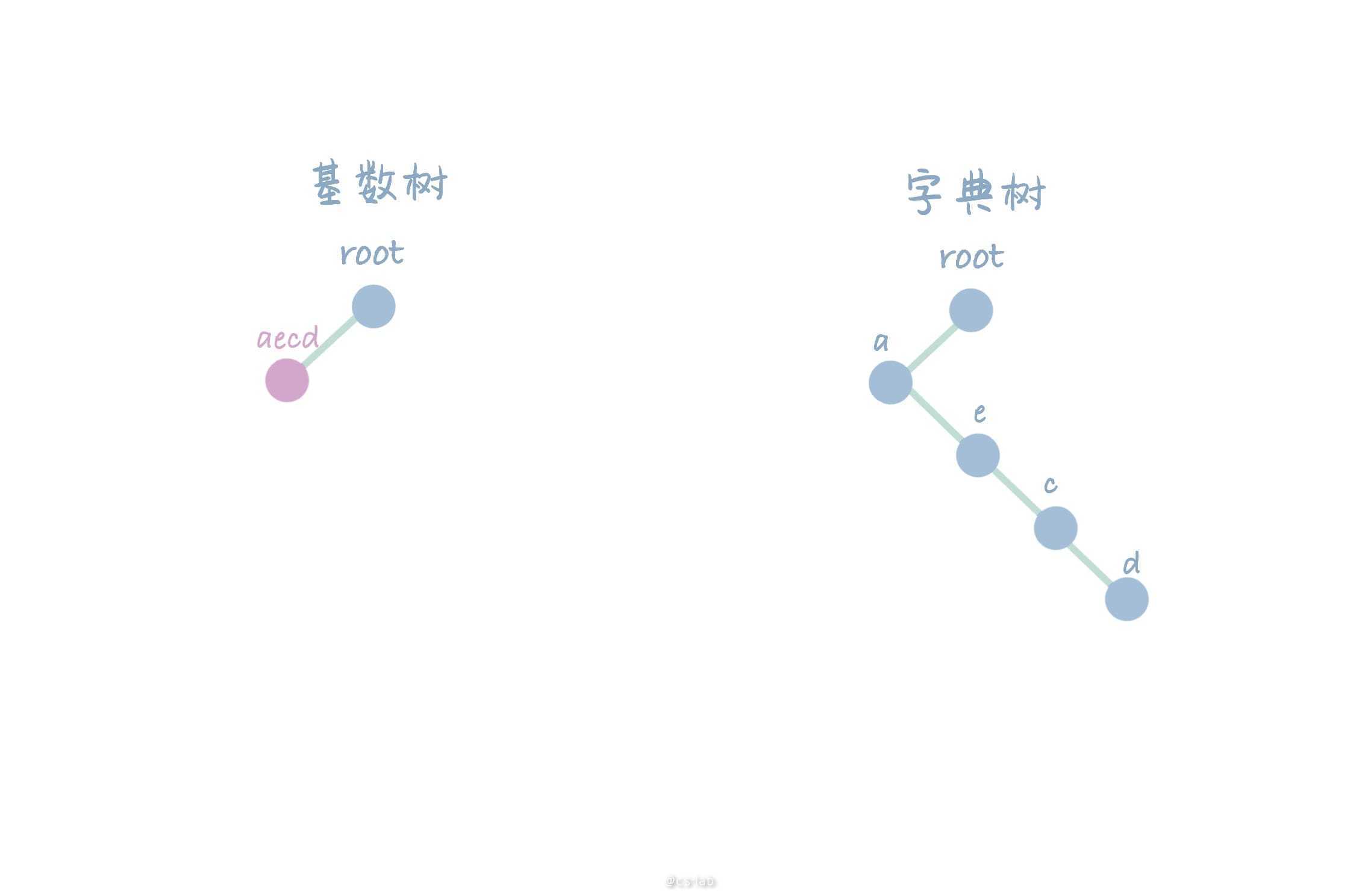
对基数树和字典树删除相同的字符串【aecd】后,两树为空。

查找
因为基数树的本质依然属于字典树,因此在查找使用上和字典树并无不同,只是因为基数树通过压缩,使得在前缀有一定规律的串在树中的深度更低,因此查找效率也较高。
近期的使用
基数树在很早之前就了解到,因为著名的 golang web 框架 gin 在 route 搜索上使用了该数据结构,所以在串查找上自然而然的想到了该数据结构。
串查找
近期的第一次相遇是在实现一个支持通配符的 EventBus 上,我预期实现一个 Golib 用于程序内部的事件驱动编程,使用方式类似:
func bobDoSomething() {
fmt.Println("Bob do something")
}
func aliceDoSomething() {
fmt.Println("Alice do something")
}
func main() {
_, _ = bus.Subscribe("partner.bob.do", bobDoSomething)
_, _ = bus.Subscribe("partner.alice.do", aliceDoSomething)
bus.Publish("partner.*.do")
}
具体的 EventBus 的代码可以参考 https://github.com/hyponet/eventbus,这是一个非常轻量的事件库,其中基数树的逻辑实现在 bus/exchange.go 中。
对于没有通配符的场景,通过 Hash 是一种非常高效且简单的实现,但是如果考虑到通配符匹配,基于树的查找更适合。
考虑到事件的 Topic 本身就是一个规律性很强的串,因此非常适合使用基数树,比如对于如下 Topic:
sys.file.file1.create
sys.file.file1.delete
sys.dir.*.delete
可进行建树:

页缓存
近期的第二次和基数树相遇是在实现一个高效的缓存上,最近在思考如何实现一个通用且高效的文件缓存,突然意识到可以参考 Linux 的 PageCache,巧合的是,PageCache 居然也是使用的基数树。
Linux 的基数树实现在 lib/radix-tree.c 中,和上文提到的不同,Linux 并不是对一个字符串进行存储,而是一个无符号长整型名为 index 的值,可以从树操作的 Api 中看出:
// 插入值
int radix_tree_insert(struct radix_tree_root *root, unsigned long index, void *item)
// 删除值
void *radix_tree_delete(struct radix_tree_root *tree, unsigned long key);
Linux 的实现复杂但又精巧,全部展开的话估计又要新开一篇文章,简单来说,Linux 的 radix tree 是围绕下面三个参数展开的:
RADIX_TREE_MAP_SHIFT定义基数,内核通过CONFIG选项,可设置为 4 或 6,默认为 6;RADIX_TREE_MAP_SIZE该数值定义指针数组 slot 的容量;RADIX_TREE_MAP_MASK使用移位与掩码操作实现位组提取;
这三个值之间的关系,可以用 Golang 下面的常量值表示:
const (
RADIX_TREE_MAP_SHIFT = 6
RADIX_TREE_MAP_SIZE = 1 << RADIX_TREE_MAP_SHIFT
RADIX_TREE_MAP_MASK = RADIX_TREE_MAP_SIZE - 1
)
要理解这三个参数的作用,首先要再次明确 Linux 基数树的存储值是无符号长整型,名为 index(而不是字符串)。对于一个数字来说,比如 16 位 int,无论其值大小,占用的 bit 数是固定的(都是 16 个 bit)。
int16(100) // 二进制表示:0000000001100100
int16(1000) // 二进制表示:0000001111101000
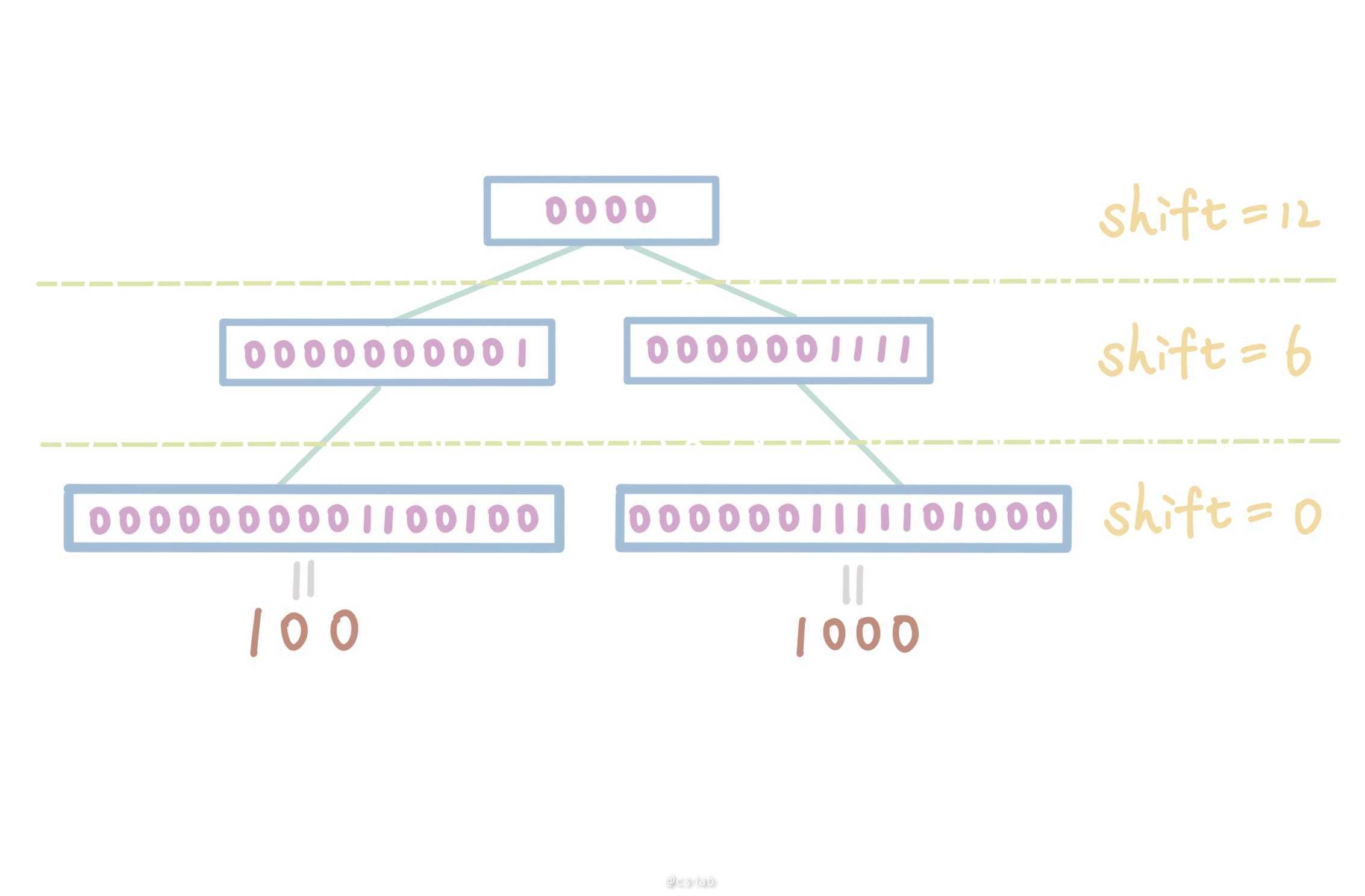
基数树的核心在于通过压缩控制树的深度,对于整形 index 来说,压缩的内容便是 bit 前缀。使用固定步长对 bit 进行右移时,可以获得确定长度的前缀。
int16(100) // shift=12 treeLevel=0 val=0000
int16(1000) // shift=12 treeLevel=0 val=0000
int16(100) // shift=6 treeLevel=1 val=0000000001
int16(1000) // shift=6 treeLevel=1 val=0000001111
int16(100) // shift=0 treeLevel=2 val=0000000001100100
int16(1000) // shift=0 treeLevel=2 val=0000001111101000
如果每次右移一个固定步长后,树的深度加一,则树的深度也是固定的(比特位数/步长)。而 RADIX_TREE_MAP_SHIFT 就是 bit 位的步长,Linux 默认值为 6,其含义是每右移 6 个 bit 为一个单位,因此对于上面的数字,可以建树为:
RADIX_TREE_MAP_SIZE 和 RADIX_TREE_MAP_MASK 本质是在实现 hash 桶操作,前者定义了桶的大小,而后者进行 hash 运算(就是取余)。对 index 右移之后,可以通过 hash 桶操作,获取确定的子节点。
最简单的 hash 操作便是取余,RADIX_TREE_MAP_MASK 是一个小技巧,如下的两种写法是等效的:
(index >> shift) % RADIX_TREE_MAP_SIZE
(index >> shift) & RADIX_TREE_MAP_MASK
对于一个 index,可以通过如下 hash 计算,获取下一个节点:
slot := index >> currentNode.shift & RADIX_TREE_MAP_MASK
currentNode = currentNode.slots[slot]
最后,通过如下 int16 的若干 index 建树举例:
int16(60) // 二进制表示:0000000000111100
int16(1000) // 二进制表示:0000001111101000
int16(10000) // 二进制表示:0010011100010000
int16(55520) // 二进制表示:1101100011100000
int16(65001) // 二进制表示:1111110111101001
可以建树为:
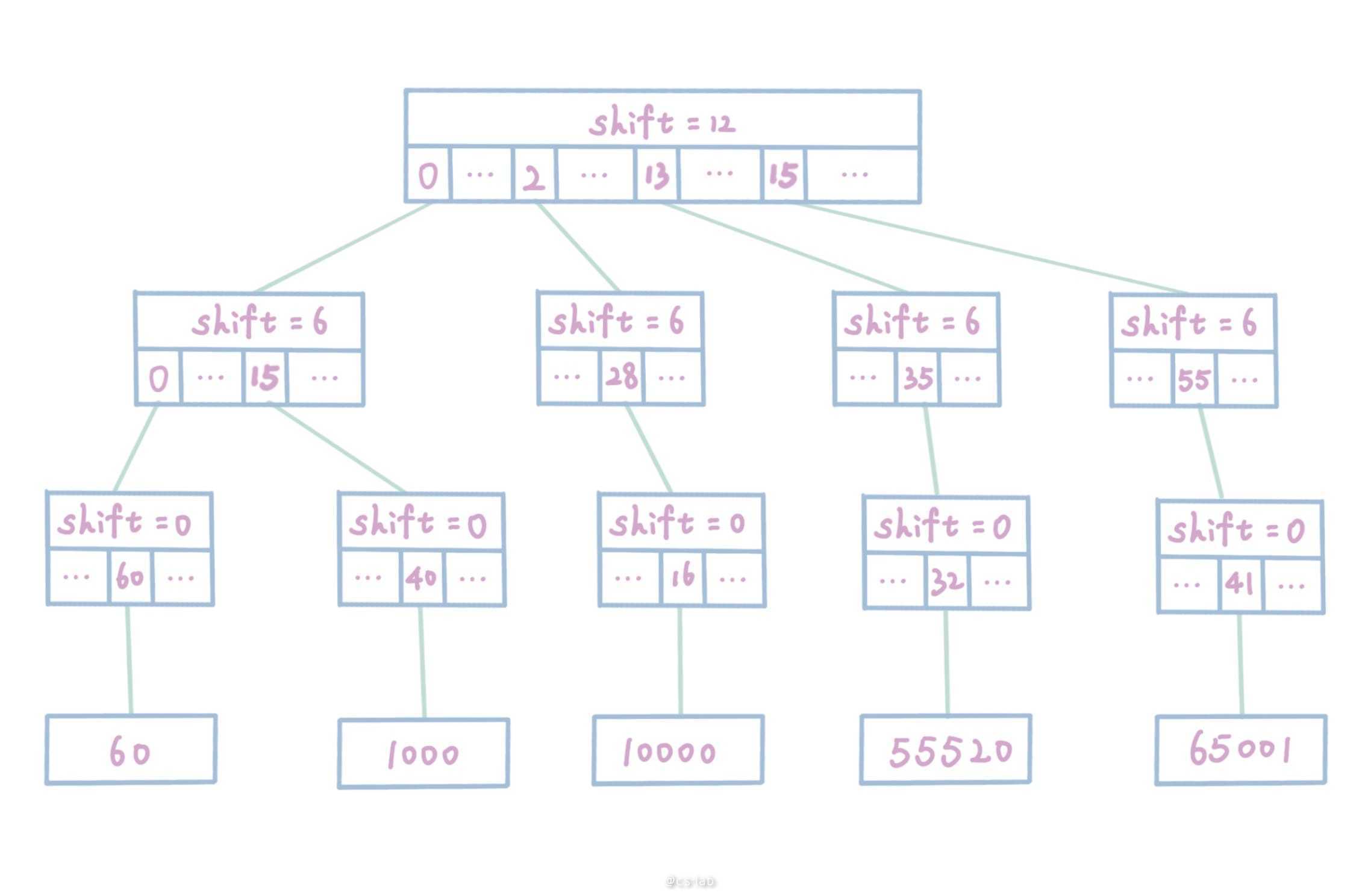
以 index=1000 举例注释:
1000 >> 12 % 64 == 0所以在slots[0]中1000 >> 6 % 64 == 15所以在slots[15]中1000 >> 0 % 64 == 40所以在slots[40]中
Linux 的基数树实现非常复杂,因为 radix-tree.c 是一个公共方法,除了页缓存,IP 寻址也用到了该逻辑,可能过于抽象,阅读起来的确很不好理解,不过我实现了一个精简的版本,可以在 https://github.com/basenana/nanafs 的 pkg/bio /pagecache.go 中找到(也可以仓库内搜 pageCache)。


