面向对象(OOP)的本质是设计并拓展自己的数据类型C++的命名规则,与C语言一样,但一般以两个下划线或下划线和大写字母打头的名称被保留给实现(编译器及其使用的资源)使用。以一个下划线开头的名称被保留给实现,用作全局标识符。
在C++所有主观风格中,一致性和精度是最重要的。
头文件climits(见下表)定义了符号常量,来表示类型的限制
define编译指令是C语言遗留下来的,C++有一种更好的创建符号常量的方法(使用关键字const)
C++11更广泛的支持大括号初始化器。对于变量初始化可以:
int emus{7};
int rheas = {12};
其次,大括号内可以不包含任何东西,在这种情况下,变量将被初始化为零。
以前,C++使用不同的方式来初始化不同的类型,初始化不同类变量的方式不于初始化常规结构的方式,而初始化常规的方式不同于初始化简单变量的方式,通过使用C++新增的大括号初始化器,初始化常规变量的方式与初始化类变量的方式更像。C++11使得将大括号初始化器用于任何类型(可以使用等号,也可以不使用),这是一种通用的初始化语法。
int被设置为对目标计算机而言最“自然”的长度。自然长度止的是计算机处理起来效率最高的长度。如果没有非常有说服力的理由来选择其他类型,则应使用int。
仅当有大整数数组时,才有必要使用short,尽管有时其长度和int是一样的,但要将程序从16位操作系统移动到32位操作系统,则用于存储int数组的内存量将加倍,而short数组不受影响,记住,节省一点就是赢一点!
如果要让cout输出十进制、十六进制和八进制,可以使用控制符dec,hex和oct,用来修改格式,使用方式,如:
cout
C++是如何确定常量的类型呢?如cout但由于l和1很像,一般使用大写L。
char可用作字符和小整数
cout.put()函数用来打印一个字符(C++的历史遗留的原因)
基于字符字符的八进制和十六进制编码来使用转义序列,如ctrl+Z的ASCII码为26,对应的八进制为032,十六进制为0x1a,可以用转义序列来便是该字符如�32,x1a。
C++有一种表示特殊字符的机制,它独立于任何特定的键盘,使用的是通用字符名。
使用通用字符名类似于转义序列,通用字符名可以用u或U打头,u后是8个十六进制位,U后面是16个十六进制位。
与int不同的是,char在默认情况下既不是没有符号的,也不是有符号的,是否有符号由C++决定(这也就是用char和wchar_t表示中文时,正数负数均表示“你好”,见下文wchar_t部分)。
如果用char来存储数值,则unsigned char和signed char的差别将非常重要,前者可以表示0~255,后者为-128~127。
如果程序要处理的字符集无法用一个8位的字节表示,如日文汉字系统。对于这种情况,C++的处理方式有两种,首先如果大型字符是实现的基本的字符集,则编译器厂商可以将char定义为一个16位的字节或则更长的字节,其次,使用一个较大的拓展字符集wchar_t(宽字符类型)
wchar_t是一种整数类型,它有足够的空间,可以表示系统使用的最大拓展字符集。
但cin和cout将输入输出看做char流,因此,适用于处理wchar_t类型,iostream头文件的最新版本提供了作用相似的工具——wcin和wcout,可用于处理wchar_t流,另外,还可以单纯加上前缀L来指示宽字符常量和宽字符串。
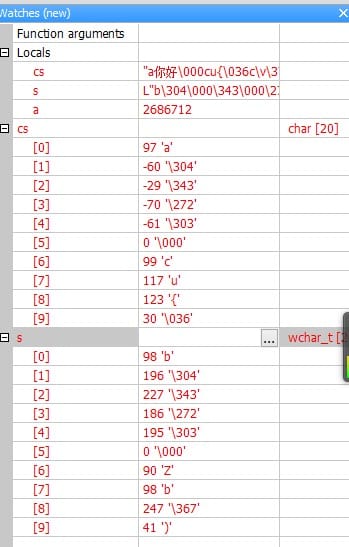
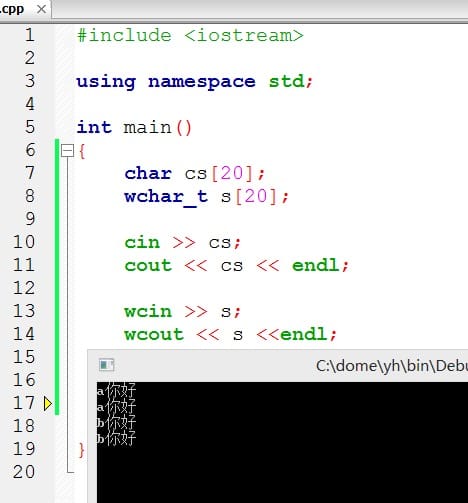
在进行国际编程或使用Unicode或ISO10646时应注意使用宽字符类型。
在进行字符串编码是,如果有特定长度和符号特征的类型,将很有帮助,因此,C++11使用前缀u(这回注意大小写)来表示char16_t字符常量和字符串常量,用前缀****U来表示char32_t常量。
和wchar_t一样,chat16_t和chat32_t也都有底层类型也都有底层类型(一种内置的整型),但底层类型可能随系统不同而不不同。
const常量比define常量要好些,首先,前者可以明确常量类型,其次,可以使用C++的作用域规则将定义限制在特定范围的函数或者文件中,第三,const可被用于更复杂的数据类型。
C++有3中浮点类型:float、double、long double,float至少32位,double至少48位且不小于float,long double至少和double一样长,通常float为32位,double为64位,long double为80、96、128位(区分在系统),它们的存储范围在cfloat(见下表)头文件中找到。
| name |
value |
stands for |
expresses |
| FLT_RADIX |
2 or greater |
RADIX |
Base for all floating-point types (float, double and long double). |
| FLT_MANT_DIG DBL_MANT_DIG LDBL_MANT_DIG |
|
MANTissa DIGits |
Precision of significand, i.e. the number of digits that conform thesignificand. |
| FLT_DIG DBL_DIG |
|
|
|
| LDBL_DIG |
6 or greater 10 or greater |
|
|
10 or greater |
DIGits |
Number of decimal digits that can be rounded into a floating-point and back without change in the number of decimal digits. |
|
| FLT_MIN_EXP DBL_MIN_EXP |
|
|
|
| LDBL_MIN_EXP |
|
MINimum EXPonent |
Minimum negative integer value for the exponent that generates a normalized floating-point number. |
| FLT_MIN_10_EXP DBL_MIN_10_EXP |
|
|
|
| LDBL_MIN_10_EXP |
-37 or smaller -37 or smaller |
|
|
-37 or smaller |
MINimum base-10 EXPonent |
Minimum negative integer value for the exponent of a base-10 expression that would generate a normalized floating-point number. |
|
| FLT_MAX_EXP DBL_MAX_EXP |
|
|
|
| LDBL_MAX_EXP |
|
MAXimum EXPonent |
Maximum integer value for the exponent that generates a normalized floating-point number. |
| FLT_MAX_10_EXP DBL_MAX_10_EXP |
|
|
|
| LDBL_MAX_10_EXP |
37 or greater 37 or greater |
|
|
37 or greater |
MAXimum base-10 EXPonent |
Maximum integer value for the exponent of a base-10 expression that would generate a normalized floating-point number. |
|
| FLT_MAX DBL_MAX |
|
|
|
| LDBL_MAX |
1E+37 or greater 1E+37 or greater |
|
|
1E+37 or greater |
MAXimum |
Maximum finite representable floating-point number. |
|
| FLT_EPSILON DBL_EPSILON |
|
|
|
| LDBL_EPSILON |
1E-5 or smaller 1E-9 or smaller |
|
|
1E-9 or smaller |
EPSILON |
Difference between 1 and the least value greater than 1 that is representable. |
|
| FLT_MIN DBL_MIN |
|
|
|
| LDBL_MIN |
1E-37 or smaller 1E-37 or smaller |
|
|
1E-37 or smaller |
MINimum |
Minimum representable floating-point number. |
|
| FLT_ROUNDS |
|
ROUND |
Rounding behavior. Possible values: -1 undetermined |
0 toward zero |
|
|
|
1 to nearest |
|
|
|
2 toward positive infinity |
|
|
|
3 toward negative infinity |
|
|
|
Applies to all floating-point types (float, double and long double). |
|
|
|
| FLT_EVAL_METHOD |
|
EVALuation METHOD |
Properties of the evaluation format. Possible values: -1 undetermined |
0 evaluate just to the range and precision of the type |
|
|
|
1 evaluate float and double as double, and long double as long double. |
|
|
|
2 evaluate all as long double Other negative values indicate an implementation-defined behavior. |
|
|
|
Applies to all floating-point types (float, double and long double). |
|
|
|
| DECIMAL_DIG |
|
DECIMAL DIGits |
Number of decimal digits that can be rounded into a floating-point type and back again to the same decimal digits, without loss in precision. |
附中文参考:
| FLT_RADIX |
用于表述三种浮点数类型的基数(Radix) |
| DECIMAL_DIG |
C++11一个可以与 long double 类型互相转化而不会损失精度的十进制数中的数字个数的最大值 |
| FLT_MIN |
float类型的最小值 |
| DBL_MIN |
double类型的最小值 |
| LDBL_MIN |
long double 类型的最小值 |
| FLT_MAX |
float 类型的最大值 |
| DBL_MAX |
double类型的最大值 |
| LDBL_MAX |
long double 类型的最大值 |
| FLT_EPSILON |
返回 float 类型的机器精度(Machine epsilon),即 1.0 与下一个可被 float 类型描述的值的差(Difference) |
| DBL_EPSILON |
返回 double 类型的机器精度,即 1.0 与下一个可被 double 类型描述的值的差 |
| LDBL_EPSILON |
返回 long double 类型的机器精度,即 1.0 与下一个可被 long double 类型描述的值的差 |
| FLT_DIG |
返回在不损失精度的前提下,float 类型可描述的基于基数 10 的数的最大数字(Digit)个数 |
| DBL_DIG |
返回在不损失精度的前提下,double 类型可描述的基于基数 10 的数的最大数字个数 |
| LDBL_DIG |
返回在不损失精度的前提下,long double 类型可描述的基于基数 10 的数的最大数字个数 |
| FLT_MANT_DIG |
返回在不损失精度的前提下,float 类型可描述的基于基数 FLT_RADIX 的数的最大数字个数 |
| DBL_MANT_DIG |
返回在不损失精度的前提下,double 类型可描述的基于基数 FLT_RADIX 的数的最大数字个数 |
| LDBL_MANT_DIG |
返回在不损失精度的前提下,long double 类型可描述的基于基数 FLT_RADIX 的数的最大数字个数 |
| FLT_MIN_EXP |
用 FLT_RADIX 的 x-1 次幂表示 float 类型的规格化(Normalized)时,x 所能取的最小负整数值 |
| DBL_MIN_EXP |
用 FLT_RADIX 的 x-1 次幂表示 double 类型的规格化时,x 所能取的最小负整数值 |
| LDBL_MIN_EXP |
用 FLT_RADIX 的 x-1 次幂表示 long double 类型的规格化时,x 所能取的最小负整数值 |
| FLT_MIN_10_EXP |
用 10 的 x 次幂表示 float 类型的规格化时,x 所能取的最小负整数值 |
| DBL_MIN_10_EXP |
用 10 的 x 次幂表示 double 类型的规格化时,x 所能取的最小负整数值 |
| LDBL_MIN_10_EXP |
用 10 的 x 次幂表示 long double 类型的规格化时,x 所能取的最小负整数值 |
| FLT_MAX_EXP |
用 FLT_RADIX 的 x-1 次幂表示 float 类型的规格化(Normalized)时,x 所能取的最大正整数值 |
| DBL_MAX_EXP |
用 FLT_RADIX 的 x-1 次幂表示 double 类型的规格化时,x 所能取的最大正整数值 |
| LDBL_MAX_EXP |
用 FLT_RADIX 的 x-1 次幂表示 long double 类型的规格化时,x 所能取的最大正整数值 |
| FLT_MAX_10_EXP |
用 10 的 x 次幂表示 float 类型的规格化时,x 所能取的最大正整数值 |
| DBL_MAX_10_EXP |
用 10 的 x 次幂表示 double 类型的规格化时,x 所能取的最大正整数值 |
| LDBL_MAX_10_EXP |
用 10 的 x 次幂表示 long double 类型的规格化时,x 所能取的最大正整数值 |
| FLT_ROUNDS |
默认的浮点数类型的舍入(Rounding)模式 |
| FLT_EVAL_METHOD |
C++11默认的浮点数类型的反规格化(Denormalization)模式 |
计算机默认将浮点型常量看做double类型,如果希望为float。则使用后缀f,如果希望long double则使用后缀L(一样大小写任意)。
C++11将使用大括号的初始化称为列表初始化,因为这种初始化常用与给复杂的数据类型提供值列表,它对类型转换的要求更严格。具体的说,列表初始化不允许“缩窄”,即变量的类型可能无法表示赋给它的值(就是我们说的精度损失)。
C++想让强制转换就像函数一样调用,因此允许
typeName(Value);
这样强制转换。
C++认为C语言的强制转换是危险的,便引入了static_cast<>,用法是:
static_cast (Value);
C++11新增了以一个工具,让编译器根据初始值的类型推断变量的类型,为此,它重新定义了auto的含义,使得auto称为不指定变量类型,编译器将把变量的类型设置于初始值相同,在STL中,auto将发挥巨大的作用!
auto i = 1; //i将为int类型
auto d = 1.0; //d将为double类型

