
当你考虑基于 Kubernetes 的能力为自己的应用锦上添花的时候,就仿佛打开了一个潘多拉魔盒,你不知道这个盒子里到底有什么,就像你不知道你所依赖的 Kubernetes 集群和集群上的应用正在、将要发生什么。
无论选择什么架构,底层基于什么运行时,可观测性始终拥有极高的优先级。有一种说法是:如果你不知道怎么运维,就不要去尝试部署。这也算是一种非常朴实的,以终为始的思考方式。
话说回来,如果拥抱了 Kubernetes,那么我们所追求的 “可观测性” 是什么样子呢?对于微服务架构,我认为有几个方面可以作为及格线:
- 集群和应用状态的可观测性
- 集群和应用的日志
- 应用间流量、调用关系和请求状态的可观测性
简单来说,就是:监控、日志、跟踪,而 Prometheus 就是在 Kubernetes 监控比较成熟的解决方案。
Prometheus
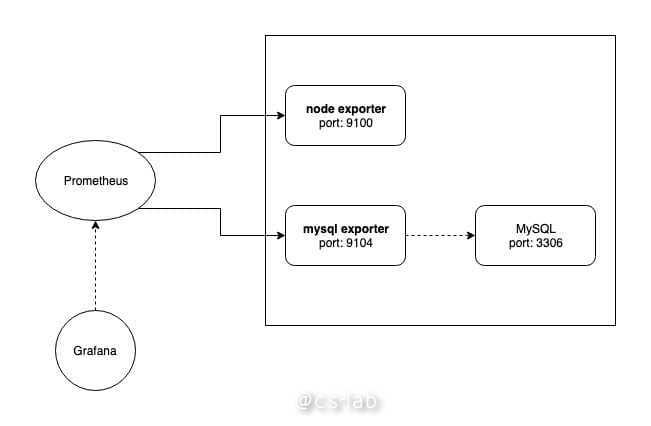
Prometheus 一款基于时序数据库的开源监控告警系统,诞生自 SoundCloud 公司。Prometheus 的基本工作原理是通过 HTTP 协议,周期性的抓取被监控组件的状态,因此被监控组件只需要实现符合规范的 HTTP 接口便可以接入,对于默认没有提供 HTTP 接口的组件,比如 Linux、MySQL 等,Prometheus 支持使用 exporter 来收集信息,并代为提供 metrics 接口。
SoundCloud 公司博客上有一篇文章简单讲解了 Prometheus 架构以及工作原理。文章中认为 Prometheus 满足的四个特性:
- A multi-dimensional data model(多维度数据模型)
- Operational simplicity(方便的部署和维护)
- Scalable data collection and decentralized architecture(灵活的数据采集)
- A powerful query language(强大的查询语言)
第一项和第四项也是时序数据库的特点,但 Prometheus 为了方便部署,默认并没有内置任何额外的存储,而是选择自己实现,对于第四个特性 Prometheus 实现了 PromQL 查询语言,可以实现强大的查询规则。
随着版本的迭代,Prometheus 的特性早已不局限于此。

从 Prometheus 的架构图可以看到,有 4 个主要组件:
- Prometheus Server
- PushGateway
- AlertManager
- WebUI
其中只有 Prometheus Server 是最重要的组件,承担着数据的采集,Prometheus 采用 pull 的方式对被监控对象进行数据采集,但是如果需要被监控对象通过 Push 将自身的状态推送给 Prometheus,可以引入 PushGateway,被监控对象将主动的将状态 Push 到 PushGateway 上,而 Prometheus Server 定期去 PushGateway 采集。
AlertManager 和 WebUI 都不是必须组件,前者可以基于采集的数据设置报警,后者可以通过 Web 界面的方式实时展示监控数据。
Prometheus Operator
Prometheus 的部署方式非常多,得益于其简单的工作原理,因此只需要将 Prometheus Server 部署到能访问到被监控对象的环境里即可。
但对于 K8s 来言,因为集群内的网络环境相对封闭、 Pod 的 IP 易变等特点,CoreOS 开源了通过 Operator(CRD) 的方式管理和部署 Prometheus (https://github.com/coreos/prometheus-operator )。
之前介绍 CRD 的文章(如何使用 CRD 拓展 Kubernetes 集群)也讲到,CRD 提供的能力取决于 CRD Controller,Prometheus Operator 便是这么一种 Controller,承担了监听自定义资源的变更,并完成后续的管理工作的职责。
安装 Operator
Prometheus Operator 的安装非常简单,在 Git 仓库的根目录下,直接 kubectl apply 其中的 bundle.yaml(镜像在 quay.io 下,需要科学上网):
git clone https://github.com/coreos/prometheus-operator.git
kubectl apply -f prometheus-operator/bundle.yaml
基本概念
Prometheus Operator 将会托管 Prometheus 的部署、管理工作,而且基于 K8s 中的 CRD,Prometheus Operator 新引入了若干 CR(自定义资源):
- Prometheus:描述将要部署的 Prometheus Server 集群
- ServiceMonitor/PodMonitor:描述了 Prometheus Server 的 Target 列表
- Alertmanager:描述 Alertmanager 集群
- PrometheusRule:描述 Prometheus 的告警规则
Prometheus Operator 的设计理念可以参考文档:https://github.com/coreos/prometheus-operator/blob/master/Documentation/design.md 。
工作原理
Prometheus Operator 通过监听上面的自定义资源(CR)的变动,并执行后续管理逻辑,入下图:
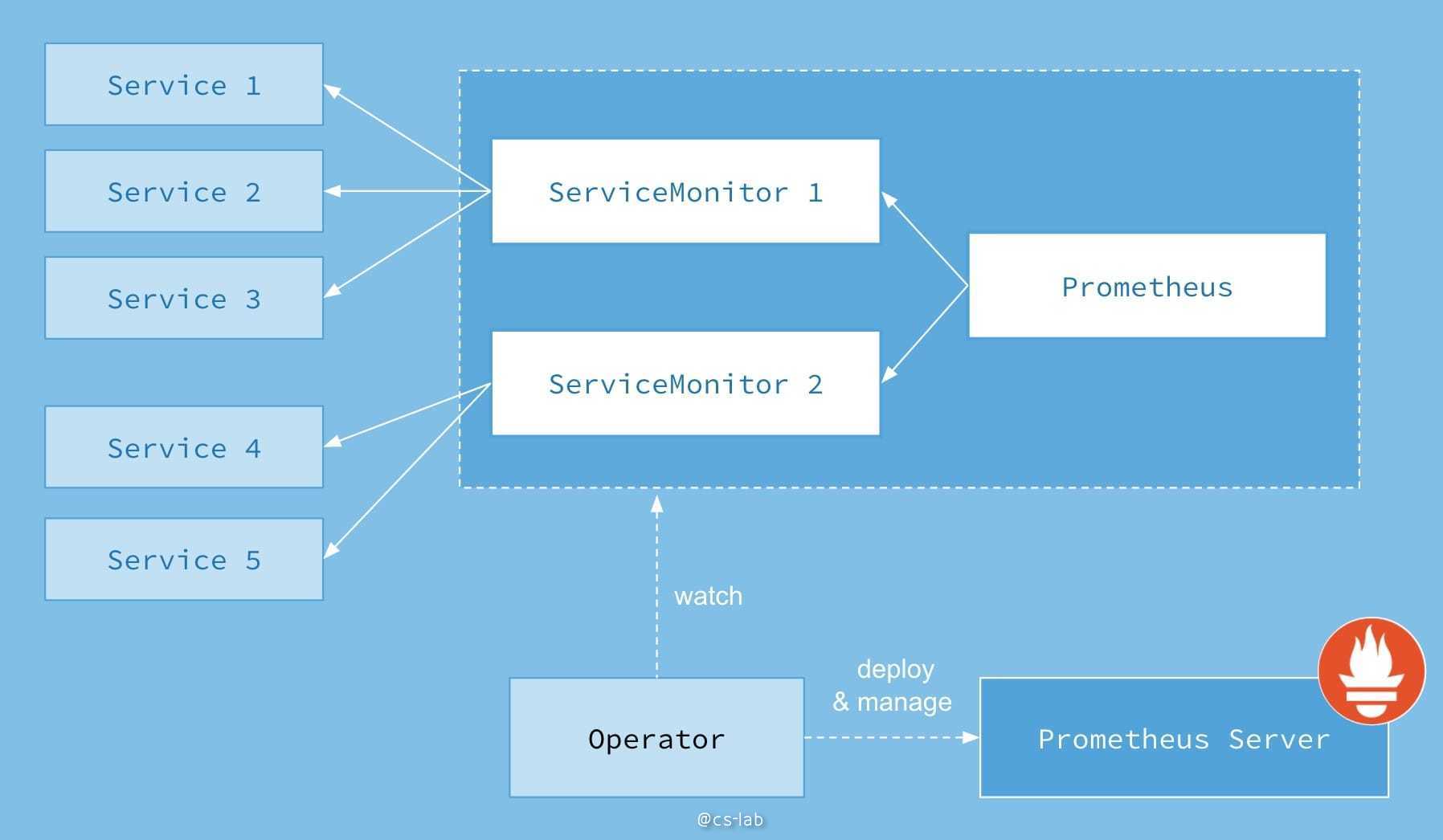
通过创建类型为 Prometheus 的资源(此处的 Prometheus 指的是 Prometheus Operator 定义的自定义资源),该 Prometheus 会通过 label selector 选择相关的 ServiceMonitor,而 ServiceMonitor 通过定义选择 Service 的 label selector 来选定需要监控的 Service ,并通过该 Service 对应的 Endpoints 获得需要监控的 Pod ip 列表。
监控应用 Demo
我们根据官方 User Guides 简单介绍一下如何使用 prometheus-operator 对应用进行监控,更多细节可以参考:https://github.com/coreos/prometheus-operator/blob/master/Documentation/user-guides/getting-started.md 。
部署被监控对象
通过 Deployment 部署有 3 个副本的应用:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 3
selector:
matchLabels:
app: example-app
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: example-app
image: fabxc/instrumented_app
ports:
- name: web
containerPort: 8080
然后创建 Service 使得该服务可以提供稳定访问入口:
kind: Service
apiVersion: v1
metadata:
name: example-app
labels:
app: example-app
spec:
selector:
app: example-app
ports:
- name: web
port: 8080
注意 Service 中定义了 app=example-app 的 label,这是 ServiceMonitor 的选择依据。
部署监控
根据 Service 中定义的 Label,我们可以定义 ServiceMonitor:
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
labels:
team: frontend
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web
ServiceMonitor 定义了 team=frontend 的 label,这也是 Prometheus 选择 ServiceMonitor 的依据。因此可以创建 Prometheus:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
enableAdminAPI: false
这时就发现,已经有 prometheus 实例被启动了:
# kubectl get po
NAME READY STATUS RESTARTS AGE
example-app-66db748757-bfqx4 1/1 Running 0 103m
example-app-66db748757-jqsh5 1/1 Running 0 103m
example-app-66db748757-jtbpc 1/1 Running 0 103m
prometheus-operator-7447bf4dcb-lzbf4 1/1 Running 0 18h
prometheus-prometheus-0 3/3 Running 0 100m
prometheus 本身提供了 WebUI,因此我们可以创建 SVC 是其暴露到集群外部访问(最好不要在公网环境做这样的操作):
apiVersion: v1
kind: Service
metadata:
name: prometheus
spec:
type: NodePort
ports:
- name: web
nodePort: 30900
port: 9090
protocol: TCP
targetPort: web
selector:
prometheus: prometheus
这时就可以看到集群内,Demo 应用的监控信息:
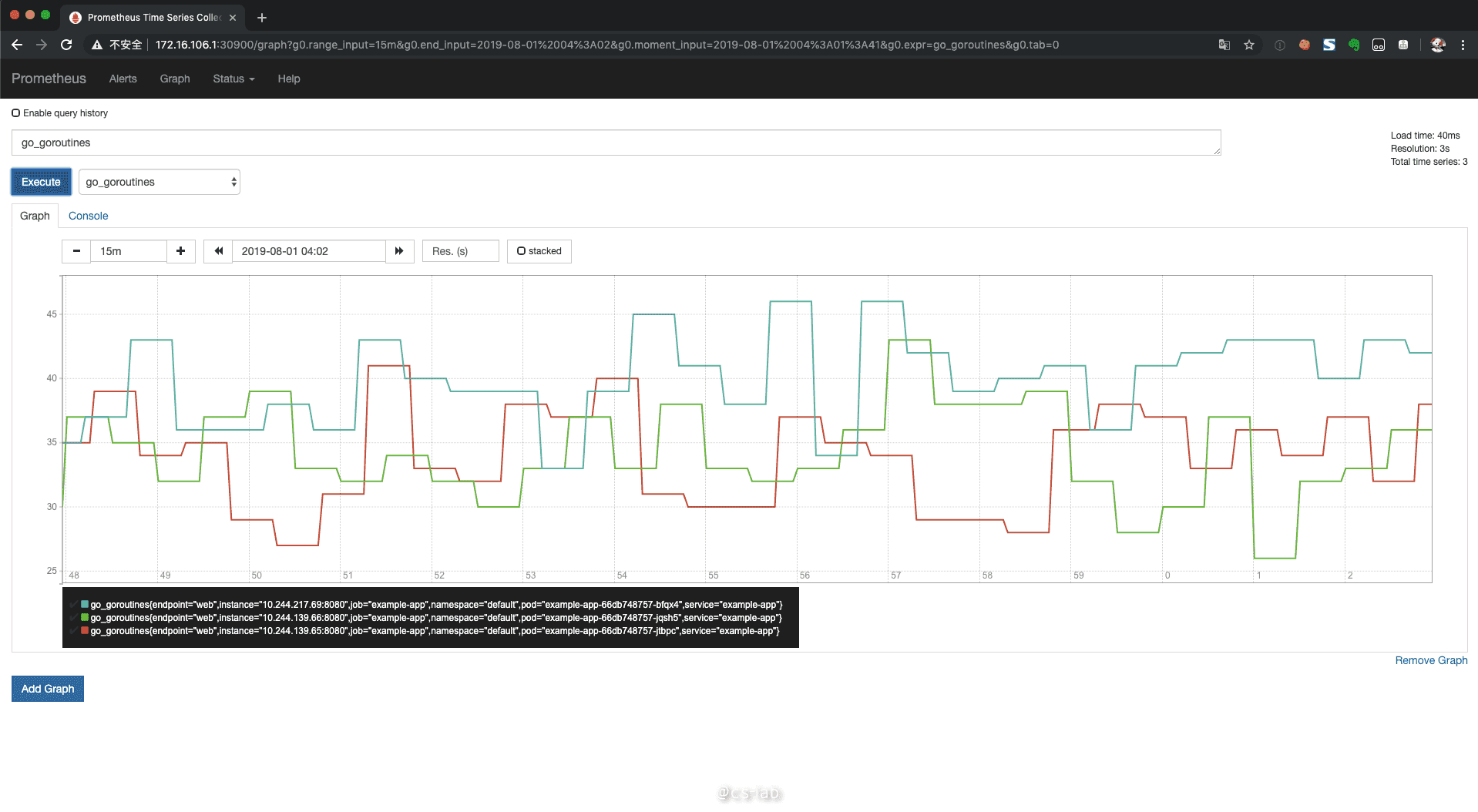
集群监控
通过这个自定义的 Demo 应该可以了解到,Prometheus 是通过 SVC 发起 HTTP 访问来获取数据,而集群监控,只不过是让 Prometheus 有能力获得 Kubernetes 组件的监控接口。同时,Prometheus 也支持以 DaemonSet 的形式部署 Node exporter,来直接收集集群节点信息。
而 Kubernetes 组件的监控数据的采集形式,则取决于集群的部署方式。如果是二进制文件方式部署,可以直接在 Node 上安装 Prometheus 并采集数据;而如果是容器部署,可以为 Kubernetes 组件创建 SVC,后续操作便和集群应用的监控方式一致了,相关文档可以参考:https://coreos.com/operators/prometheus/docs/latest/user-guides/cluster-monitoring.html 。


