开放黑客松使用的数据库是 MongoDB,在容器化中,数据的安全问题是重中之重。
存储问题
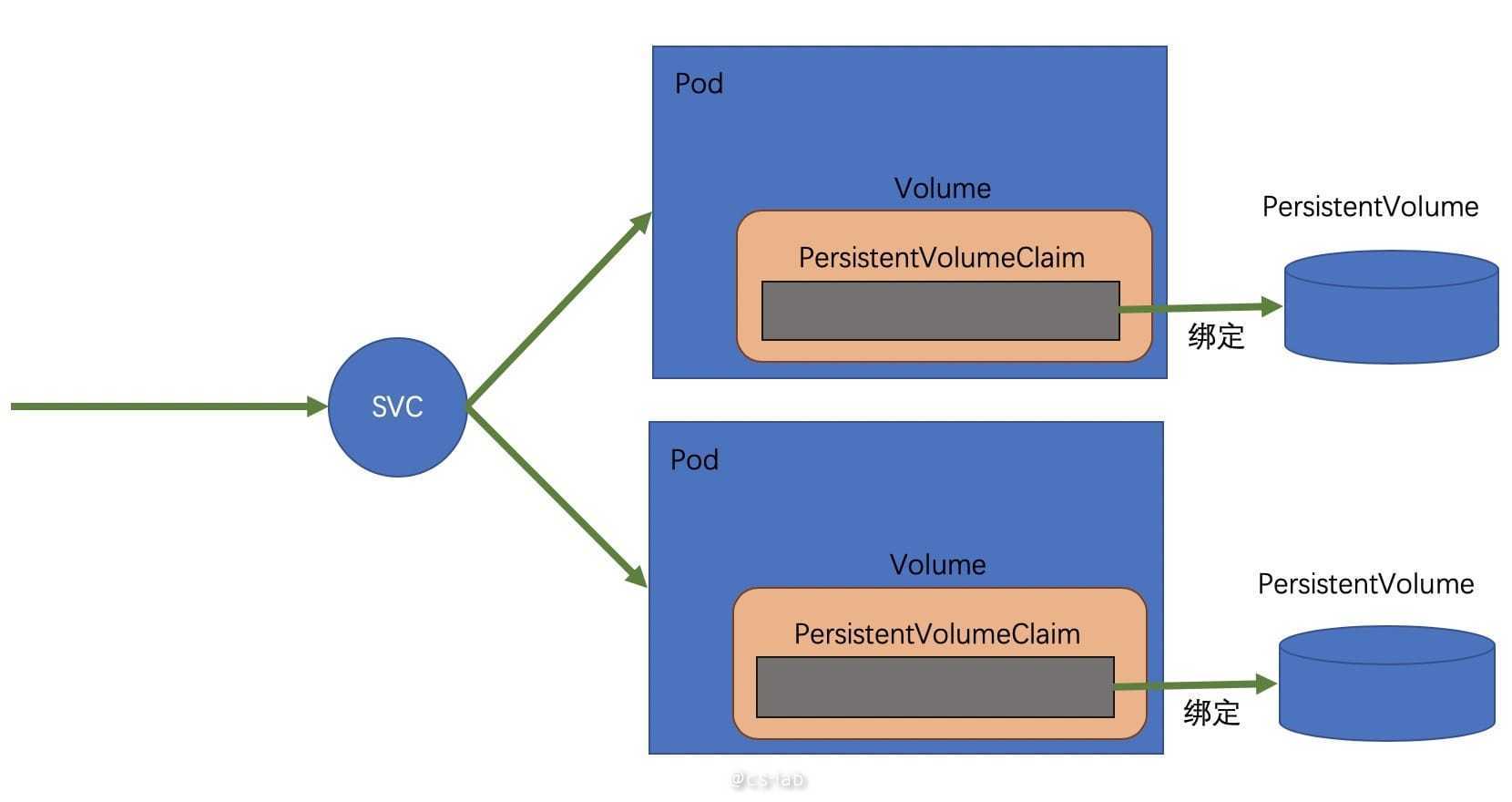
有状态的应用在 Kubernetes 上部署时需要使用 PersistentVolume,但是如果 PV 底层的存储不可靠,即使使用 PV,依然不能保证数据安全。
在一般的使用场景下,应用需要定义一个 PersistentVolumeClaim 来描述需要的存储资源,并在 Pod 中使用该 PersistentVolumeClaim,集群会根据 PersistentVolumeClaim 里的描述,创建或寻找一个 PersistentVolume 与之绑定,因此当 Pod 对容器内的 Volume 进行读写时,数据会被持久化到 PersistentVolume 中。

对于 PersistentVolume 的创建有两种方式,第一种是由集群管理员手动创建若干个 PersistentVolume,当 PersistentVolumeClaim 被创建时,集群会寻找满足要求的 PersistentVolume 并与之绑定。当 PersistentVolumeClaim 被删除时,绑定关系解除,PersistentVolume 被触发回收策略。
第二种方式是创建默认的 StorageClass,并使用支持自动拓展的底层存储,当 PersistentVolumeClaim 被创建时,集群会自动在底层存储中创建一个 PersistentVolume 并与之绑定。当 PersistentVolumeClaim 被删除时,PersistentVolume 也会被自动清理。
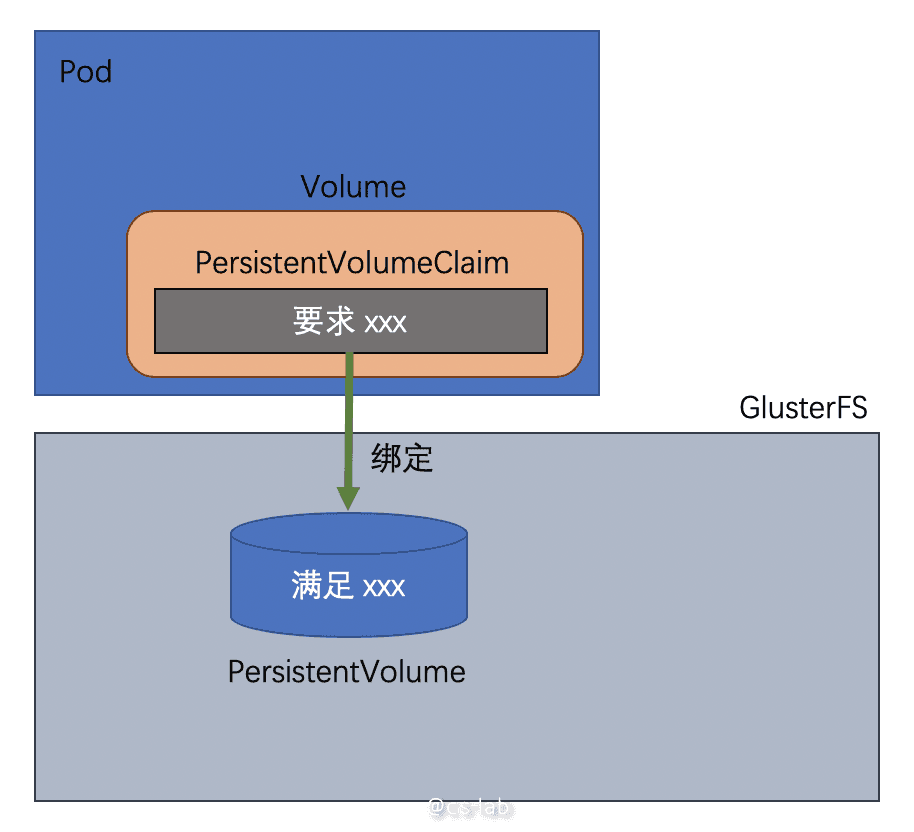
但无论这两种哪个方式,都需要考虑底层存储是什么,也就是 PersistentVolume 的数据到底存放在哪里。如果是自建集群,可以考虑 Ceph,GlusterFS。
对于公有云服务,可以考虑服务提供商提供的存储服务,比如在华为云 CCE(托管 Kubernetes 集群)中,可以使用云硬盘来作为底层存储:https://support.huaweicloud.com/usermanual-cce/cce_01_0044.html
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: mongo-pv-claim
namespace: ohp
annotations:
volume.beta.kubernetes.io/storage-class: sata
volume.beta.kubernetes.io/storage-provisioner: flexvolume-huawei.com/fuxivol
labels:
failure-domain.beta.kubernetes.io/region: cn-north-1
failure-domain.beta.kubernetes.io/zone: cn-north-1a
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi
单实例部署
对于没有高可用需求的场景,可以使用单实例部署,即只需要运行一个 MongoDB 实例,并为该实例挂载一个可持久化的存储。
apiVersion: v1
kind: Secret
metadata:
name: mongo-auth
namespace: ohp
type: Opaque
data:
username: cm9vdAo=
password: cGFzc3dvcmQK
---
apiVersion: v1
kind: Service
metadata:
name: mongo
namespace: ohp
spec:
ports:
- port: 27017
selector:
app: mongo
clusterIP: None
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: mongo
namespace: ohp
spec:
selector:
matchLabels:
app: mongo
strategy:
type: Recreate
template:
metadata:
labels:
app: mongo
spec:
containers:
- image: mongo
name: mongo
env:
- name: MONGO_INITDB_ROOT_USERNAME
valueFrom:
secretKeyRef:
name: mongo-auth
key: username
- name: MONGO_INITDB_ROOT_PASSWORD
valueFrom:
secretKeyRef:
name: mongo-auth
key: password
ports:
- containerPort: 27017
name: mongo
volumeMounts:
- name: db-persistent-storage
mountPath: /data/db
volumes:
- name: db-persistent-storage
persistentVolumeClaim:
claimName: mongo-pv-claim
其中有两点要注意:
- Mongo 的认证用户名和密码配置在
Secret中 - SVC 指定了 ClusterIP 为 None,意味着 Service 将直接解析为 PodIP
- Deployment 的发布策略为重建,因为 PV 只能挂载到一个 Pod 中,因此应该避免同时出现多个 Pod(该 Deployment 也不能扩容)
高可用集群
Mongo 做 HA 的方案有很多种,Kubernetes Blog 里有一篇讲如何使用 GCE 搭建 HA mongoDB,用到的是副本集的高可用方案,副本集的方案在 Kubernetes 中应是最简单的,只需要定义一个 StatefulSet 就可以解决。
通过 StatefulSet 维持多个 Pod,每个 Pod 都拥有一个 PV 进行持久化存储: