这篇文章将讲解 Python 并发编程的基本操作。并发和并行是对孪生兄弟,概念经常混淆。并发是指能够多任务处理,并行则是是能够同时多任务处理。Erlang 之父 Joe Armstrong 有一张非常有趣的图说明这两个概念:
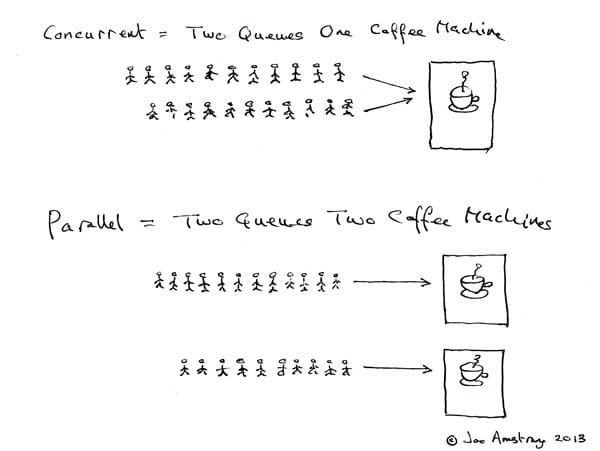
我个人更喜欢的一种说法是:并发是宏观并行而微观串行。
GIL
虽然 Python 自带了很好的类库支持多线程/进程编程,但众所周知,因为 GIL 的存在,Python 很难做好真正的并行。
GIL 指全局解释器锁,对于 GIL 的介绍:
全局解释器锁(英语:Global Interpreter Lock,缩写GIL),是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。
- 维基百科
其实与其说 GIL 是 Python 解释器的限制,不如说是 CPython 的限制,因为 Python 为了保障性能,底层大多使用 C 实现的,而 CPython 的内存管理并不是线程安全的,为了保障整体的线程安全,解释器便禁止多线程的并行执行。
因为 Python 社区认为操作系统的线程调度已经非常成熟了,没有必要自己再实现一遍,因此 Python 的线程切换基本是依赖操作系统,在实际的使用中,对于单核 CPU,GIL 并没有太大的影响,但对于多核 CPU 却引入了线程颠簸(thrashing)问题。
线程颠簸是指作为单一资源的 GIL 锁,在被多核心竞争强占时资源额外消耗的现象。
比如下图,线程1 在释放 GIL 锁后,操作系统唤醒了 线程2,并将 线程2 分配给 核心2 执行,但是如果此时 线程2 却没有成功获得 GIL 锁,只能再次被挂起。此时切换线程、切换上下文的资源都将白白浪费。
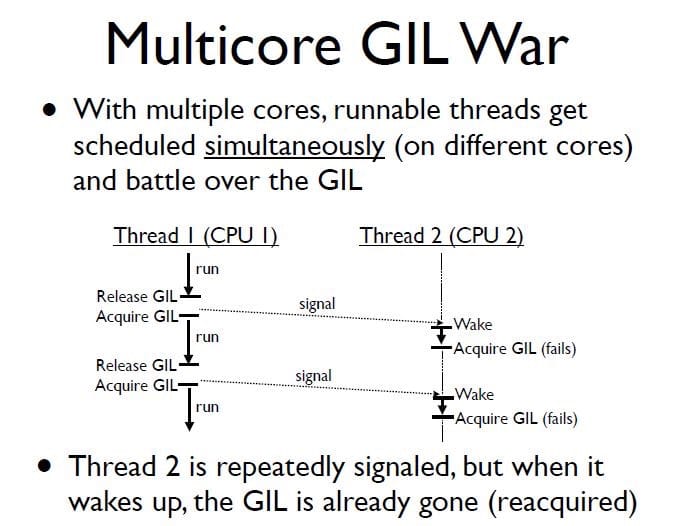
因此,Python 多线程程序在多核 CPU 机器下的性能不一定比单核高。那么如果是计算密集型的程序,一般还是考虑用 C 重写关键部分,或者使用多进程避开 GIL。
多线程
在 Python 中使用多线程,有 thread 和 threading 可供原则,thread 提供了低级别的、原始的线程以及一个简单的锁,因为 thread 过于简陋,线程管理容易出现人为失误,因此官方更建议使用 threading,而 threading 也不过是对 thread 的封装和补充。(Python3 中 thread 被改名为 _thread)。
在 Python 中创建线程非常简单:
import time
import threading
def do_task(task_name):
print("Get task: {}".format(task_name))
time.sleep(1)
print("Finish task: {}".format(task_name))
if __name__ == "__main__":
tasks = []
for i in range(0, 10):
# 创建 task
tasks.append(threading.Thread(
target=do_task,
args=("task_{}".format(i),)))
for t in tasks:
# 开始执行 task
t.start()
for t in tasks:
# 等待 task 执行完毕
# 完毕前会阻塞住主线程
t.join()
print("Finish.")
直接创建线程简单优雅,如果逻辑复杂,也可以通过继承 Thread 基类完成多线程:
import time
import threading
class MyTask(threading.Thread):
def __init__(self, task_name):
super(MyTask, self).__init__()
self.task_name = task_name
def run(self):
print("Get task: {}".format(self.task_name))
time.sleep(1)
print("Finish task: {}".format(self.task_name))
if __name__ == "__main__":
tasks = []
for i in range(0, 10):
# 创建 task
tasks.append(MyTask("task_{}".format(i)))
for t in tasks:
# 开始执行 task
t.start()
for t in tasks:
# 等待 task 执行完毕
# 完毕前会阻塞住主线程
t.join()
print("Finish.")
多进程
在 Python 中,可以使用 multiprocessing 库来实现多进程编程,和多线程一样,有两种方法可以使用多进程编程。
直接创建进程:
import time
import random
import multiprocessing
def do_something(task_name):
print("Get task: {}".format(task_name))
time.sleep(random.randint(1, 5))
print("Finish task: {}".format(task_name))
if __name__ == "__main__":
tasks = []
for i in range(0, 10):
# 创建 task
tasks.append(multiprocessing.Process(
target=do_something,
args=("task_{}".format(i),)))
for t in tasks:
# 开始执行 task
t.start()
for t in tasks:
# 等待 task 执行完毕
# 完毕前会阻塞住主线程
t.join()
print("Finish.")
继承进程父类:
import time
import random
import multiprocessing
class MyTask(multiprocessing.Process):
def __init__(self, task_name):
super(MyTask, self).__init__()
self.task_name = task_name
def run(self):
print("Get task: {}".format(self.task_name))
time.sleep(random.randint(1, 5))
print("Finish task: {}".format(self.task_name))
if __name__ == "__main__":
tasks = []
for i in range(0, 10):
# 创建 task
tasks.append(MyTask("task_{}".format(i)))
for t in tasks:
# 开始执行 task
t.start()
for t in tasks:
# 等待 task 执行完毕
# 完毕前会阻塞住主线程
t.join()
print("Finish.")
multiprocessing 除了常用的多进程编程外,我认为它最大的意义在于提供了一套规范,在该库下有一个 dummy 模块,即 multiprocessing.dummy,里面对 threading 进行封装,提供了和 multiprocessing 相同 API 的线程实现,换句话说,class::multiprocessing.Process 提供的是进程任务类,而 class::multiprocessing.dummy.Process,也正是有 multiprocessing.dummy 的存在,可以快速的讲一个多进程程序改为多线程:
import time
import random
from multiprocessing.dummy import Process
class MyTask(Process):
def __init__(self, task_name):
super(MyTask, self).__init__()
self.task_name = task_name
def run(self):
print("Get task: {}".format(self.task_name))
time.sleep(random.randint(1, 5))
print("Finish task: {}".format(self.task_name))
if __name__ == "__main__":
tasks = []
for i in range(0, 10):
# 创建 task
tasks.append(MyTask("task_{}".format(i)))
for t in tasks:
# 开始执行 task
t.start()
for t in tasks:
# 等待 task 执行完毕
# 完毕前会阻塞住主线程
t.join()
print("Finish.")
无论是多线程还是多进程编程,这也是我一般会选择 multiprocessing 的原因。
除了直接创建进程,还可以用进程池(或者 multiprocessing.dummy 里的进程池):
import time
import random
from multiprocessing import Pool
def do_task(task_name):
print("Get task: {}".format(task_name))
time.sleep(random.randint(1, 5))
print("Finish task: {}".format(task_name))
if __name__ == "__main__":
pool = Pool(5)
for i in range(0, 10):
# 创建 task
pool.apply_async(do_task, ("task_{}".format(i),))
pool.close()
pool.join()
print("Finish.")
线程池:
import time
import random
from multiprocessing.dummy import Pool
def do_task(task_name):
print("Get task: {}".format(task_name))
time.sleep(random.randint(1, 5))
print("Finish task: {}".format(task_name))
if __name__ == "__main__":
pool = Pool(5)
for i in range(0, 10):
# 创建 task
pool.apply_async(do_task, ("task_{}".format(i),))
pool.close()
pool.join()
print("Finish.")
这里示例有个问题,pool 在 join 前需要 close 掉,否则就会抛出异常,不过 Python 之禅的作者 Tim Peters 给出解释:
As to Pool.close(), you should call that when - and only when - you're never going to submit more work to the Pool instance. So Pool.close() is typically called when the parallelizable part of your main program is finished. Then the worker processes will terminate when all work already assigned has completed.
It's also excellent practice to call Pool.join() to wait for the worker processes to terminate. Among other reasons, there's often no good way to report exceptions in parallelized code (exceptions occur in a context only vaguely related to what your main program is doing), and Pool.join() provides a synchronization point that can report some exceptions that occurred in worker processes that you'd otherwise never see.
同步原语
在多进程编程中,因为进程间的资源隔离,不需要考虑内存的线程安全问题,而在多线程编程中便需要同步原语来保存线程安全,因为 Python 是一门简单的语言,很多操作都是封装的操作系统 API,因此支持的同步原语蛮全,但这里只写两种常见的同步原语:锁和信号量。
通过使用锁可以用来保护一段内存空间,而信号量可以被多个线程共享。
在 threading 中可以看到 Lock 锁和 RLock 重用锁两种锁,区别如名。这两种锁都只能被一个线程拥有,第一种锁只能被获得一次,而重用锁可以被多次获得,但也需要同样次数的释放才能真正的释放。
当多个线程对同一块内存空间同时进行修改的时候,经常遇到奇怪的问题:
import time
import random
from threading import Thread, Lock
count = 0
def do_task():
global count
time.sleep(random.randint(1, 10) * 0.1)
tmp = count
tmp += 1
time.sleep(random.randint(1, 10) * 0.1)
count = tmp
print(count)
if __name__ == "__main__":
tasks = []
for i in range(0, 10):
tasks.append(Thread(target=do_task))
for t in tasks:
t.start()
for t in tasks:
t.join()
print("Finish. Count = {}".format(count))
如上就是典型的非线程安全导致 count 没有达到预期的效果。而通过锁便可以控制某一段代码,或者说某段内存空间的访问:
import time
import random
from threading import Thread, Lock
count = 0
lock = Lock()
def do_task():
lock.acquire()
global count
time.sleep(random.randint(1, 10) * 0.1)
tmp = count
tmp += 1
time.sleep(random.randint(1, 10) * 0.1)
count = tmp
print(count)
lock.release()
if __name__ == "__main__":
tasks = []
for i in range(0, 10):
tasks.append(Thread(target=do_task))
for t in tasks:
t.start()
for t in tasks:
t.join()
print("Finish. Count = {}".format(count))
当然,上述例子非常暴力,直接强行把并发改为串行。
对于信号量常见于有限资源强占的场景,可以定义固定大小的信号量供多个线程获取或者释放,从而控制线程的任务执行,比如下面的例子,控制最多有 5 个任务在执行:
import time
import random
from threading import Thread, BoundedSemaphore
sep = BoundedSemaphore(5)
def do_task(task_name):
sep.acquire()
print("do Task: {}".format(task_name))
time.sleep(random.randint(1, 10))
sep.release()
if __name__ == "__main__":
tasks = []
for i in range(0, 10):
tasks.append(Thread(target=do_task, args=("task_{}".format(i),)))
for t in tasks:
t.start()
for t in tasks:
t.join()
print("Finish.")
Queue 和 Pipe
因为多进程的内存隔离,不会存在内存竞争的问题。但同时,多个进程间的数据共享成为了新的问题,而进程间通信常见:队列,管道,信号。
这里只讲解队列和管道。
队列常见于双进程模型,一般用作生产者-消费者模式,由生产者进程向队列中发布任务,并由消费者从队列首部拿出任务进行执行:
import time
from multiprocessing import Process, Queue
class Task1(Process):
def __init__(self, queue):
super(Task1, self).__init__()
self.queue = queue
def run(self):
item = self.queue.get()
print("get item: [{}]".format(item))
class Task2(Process):
def __init__(self, queue):
super(Task2, self).__init__()
self.queue = queue
def run(self):
print("put item: [Hello]")
time.sleep(1)
self.queue.put("Hello")
if __name__ == "__main__":
queue = Queue()
t1 = Task1(queue)
t2 = Task2(queue)
t1.start()
t2.start()
t1.join()
print("Finish.")
理论上每个进程都可以向队列里的读或者写,可以认为队列是半双工路线。但是往往只有特定的读进程(比如消费者)和写进程(比如生产者),尽管这些进程只是开发者自己定义的。
而 Pipe 更像一个全工路线:
import time
from multiprocessing import Process, Pipe
class Task1(Process):
def __init__(self, pipe):
super(Task1, self).__init__()
self.pipe = pipe
def run(self):
item = self.pipe.recv()
print("Task1: recv item: [{}]".format(item))
print("Task1: send item: [Hi]")
self.pipe.send("Hi")
class Task2(Process):
def __init__(self, pipe):
super(Task2, self).__init__()
self.pipe = pipe
def run(self):
print("Task2: send item: [Hello]")
time.sleep(1)
self.pipe.send("Hello")
time.sleep(1)
item = self.pipe.recv()
print("Task2: recv item: [{}]".format(item))
if __name__ == "__main__":
pipe = Pipe()
t1 = Task1(pipe[0])
t2 = Task2(pipe[1])
t1.start()
t2.start()
t1.join()
t2.join()
print("Finish.")
库
除了上面介绍的 threading 和 multiprocessing 两个库外,还有一个好用的令人发指的库 concurrent.futures。和前面两个库不同,这个库是更高等级的抽象,隐藏了很多底层的东西,但也因此非常好用。用官方的例子:
with ThreadPoolExecutor(max_workers=1) as executor:
future = executor.submit(pow, 323, 1235)
print(future.result())
该库中自带了进程池和线程池,可以通过上下文管理器来管理,而且对于异步任务执行完后,结果的获得也非常简单。再拿一个官方的多进程计算的例子作为结束:
import concurrent.futures
import math
PRIMES = [
112272535095293,
112582705942171,
112272535095293,
115280095190773,
115797848077099,
1099726899285419]
def is_prime(n):
if n % 2 == 0:
return False
sqrt_n = int(math.floor(math.sqrt(n)))
for i in range(3, sqrt_n + 1, 2):
if n % i == 0:
return False
return True
def main():
with concurrent.futures.ProcessPoolExecutor() as executor:
for number, prime in zip(PRIMES, executor.map(is_prime, PRIMES)):
print('%d is prime: %s' % (number, prime))
if __name__ == '__main__':
main()


