赫夫曼树(也有人叫哈夫曼树),又称最优树,是一类带权路经最短的树。
最优二叉树
从树中一个结点到另一个结点之间的分支构成这两个结点之间的路经,从路经上的分支数目称作路经长度。 树的路经长度是从树根到每一个结点的路经长度之和。 考虑带权的结点。结点的带权路经长度为从该结点到树根之间的路经长度与结点上权的乘积。树的带权路经长度为树中所有叶子结点带权路经长度之和。 假设有n个带权值{w1,w2,...,wn},试构造一棵n个叶子结点的二叉树,每一个叶子结点带权为wi,则其中带权路经WPL最小的二叉树称做最优二叉树和赫夫曼树。 则这种树的优在哪了。举个简答的例子,在连续if else结构中,经常需要一层层的向下判断,那么,如何安排if的条件,来让比较的次数最少呢?这便是根据对符合条件的数据的频率做权值,调整if else 的结构。
构造赫夫曼树
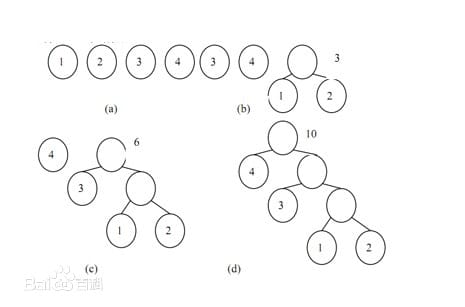
赫夫曼最早给出了一个带有一般规律的算法,俗称赫夫曼算法:
- 根据给定的n个权值{w1,w2,...,wn}构成n棵二叉树的集合F={T1,T2,...,Tn},其中每一棵二叉树Ti中只有一个带权Wi的根结点,其左右子树为空
- 在F中选取两颗根结点的权值最小的树作为左右子树构造一棵新的二叉树,且置新的二叉树的根结点的权值为其左、右子树上根结点的权值之和
- 在F中删除这两棵树,通知将新的的二叉树加入F中
- 重复2,3知道F中仅含有一棵树,这棵树便是赫夫曼树
赫夫曼编码
赫夫曼编码是赫夫曼树的一个直接应用,说的是知道一些词的频率,然后将这些字母转化为01编码,怎么转化能然解析出来的编码长度最短。 需要注意的是,要保证编码没有二义性,必须任一个字符的编码都不能是另一个编码的前缀,这种编码方式称为前缀编码。 可以利用二叉树来设计二进制的前缀编码(左孩子为0有孩子为1)。 由于赫夫曼中没有度为1的结点(严格的二叉树),则一棵有n个叶子结点的赫夫曼树共有2n-1个结点,可以存储在一个大小为2n-1的一维数组中。 由于在构成赫夫曼树之后,求编码需从叶子结点出发走一条从叶子到根的路经;而为译码需从根到叶子的路经,则对每个结点而言,既需知双亲,有需知孩子结点的信息,因此,可以用三叉链表或用结构数组模拟三叉链表。
void HuffmanCoding(HuffmanTree &HT, HuffmanCode &HC, int *w, int n) {
// w存放n个字符的权值(均>0),构造哈夫曼树HT,
// 并求出n个字符的哈夫曼编码HC
int i, j, m, s1, s2, start;
char *cd;
unsigned int c, f;
if (n<=1) return;
m = 2 * n - 1;
HT = (HuffmanTree)malloc((m+1) * sizeof(HTNode)); // 0号单元未用
for (i=1; i<=n; i++) { //初始化
HT[i].weight=w[i-1];
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
}
for (i=n+1; i<=m; i++) { //初始化
HT[i].weight=0;
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
}
printf("n哈夫曼树的构造过程如下所示:n");
printf("HT初态:n 结点 weight parent lchild rchild");
for (i=1; i<=m; i++)
printf("n%4d%8d%8d%8d%8d",i,HT[i].weight,
HT[i].parent,HT[i].lchild, HT[i].rchild);
printf(" 按任意键,继续 ...");
getch();
for (i=n+1; i<=m; i++) { // 建哈夫曼树
// 在HT[1..i-1]中选择parent为0且weight最小的两个结点,
// 其序号分别为s1和s2。
Select(HT, i-1, s1, s2);
HT[s1].parent = i; HT[s2].parent = i;
HT[i].lchild = s1; HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
printf("nselect: s1=%d s2=%dn", s1, s2);
printf(" 结点 weight parent lchild rchild");
for (j=1; j<=i; j++)
printf("n%4d%8d%8d%8d%8d",j,HT[j].weight,
HT[j].parent,HT[j].lchild, HT[j].rchild);
printf(" 按任意键,继续 ...");
getch();
}
//--- 从叶子到根逆向求每个字符的哈夫曼编码 ---
cd = (char *)malloc(n*sizeof(char)); // 分配求编码的工作空间
cd[n-1] = '�'; // 编码结束符。
for (i=1; i<=n; ++i) { // 逐个字符求哈夫曼编码
start = n-1; // 编码结束符位置
for (c=i, f=HT[i].parent; f!=0; c=f, f=HT[f].parent)
// 从叶子到根逆向求编码
if (HT[f].lchild==c) cd[--start] = '0';
else cd[--start] = '1';
HC[i] = (char *)malloc((n-start)*sizeof(char));
// 为第i个字符编码分配空间
strcpy(HC[i], &cd[start]); // 从cd复制编码(串)到HC
}
free(cd); // 释放工作空间
} // HuffmanCoding
void HuffmanCoding(HuffmanTree &HT, HuffmanCode &HC, int *w, int n) {
// w存放n个字符的权值(均>0),构造哈夫曼树HT,
// 并求出n个字符的哈夫曼编码HC
int i, j, m, s1,s2;
char *cd;
int p;
int cdlen;
if (n<=1) return;
m = 2 * n - 1;
HT = (HuffmanTree)malloc((m+1) * sizeof(HTNode)); // 0号单元未用
for (i=1; i<=n; i++) { //初始化
HT[i].weight=w[i-1];
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
}
for (i=n+1; i<=m; i++) { //初始化
HT[i].weight=0;
HT[i].parent=0;
HT[i].lchild=0;
HT[i].rchild=0;
}
printf("n哈夫曼树的构造过程如下所示:n");
printf("HT初态:n 结点 weight parent lchild rchild");
for (i=1; i<=m; i++)
printf("n%4d%8d%8d%8d%8d",i,HT[i].weight,
HT[i].parent,HT[i].lchild, HT[i].rchild);
printf(" 按任意键,继续 ...");
getch();
for (i=n+1; i<=m; i++) { // 建哈夫曼树
// 在HT[1..i-1]中选择parent为0且weight最小的两个结点,
// 其序号分别为s1和s2。
Select(HT, i-1, s1, s2);
HT[s1].parent = i; HT[s2].parent = i;
HT[i].lchild = s1; HT[i].rchild = s2;
HT[i].weight = HT[s1].weight + HT[s2].weight;
printf("nselect: s1=%d s2=%dn", s1, s2);
printf(" 结点 weight parent lchild rchild");
for (j=1; j<=i; j++)
printf("n%4d%8d%8d%8d%8d",j,HT[j].weight,
HT[j].parent,HT[j].lchild, HT[j].rchild);
printf(" 按任意键,继续 ...");
getch();
}
//------无栈非递归遍历哈夫曼树,求哈夫曼编码
cd = (char *)malloc(n*sizeof(char)); // 分配求编码的工作空间
p = m; cdlen = 0;
for (i=1; i<=m; ++i) // 遍历哈夫曼树时用作结点状态标志
HT[i].weight = 0;
while (p) {
if (HT[p].weight==0) { // 向左
HT[p].weight = 1;
if (HT[p].lchild != 0) { p = HT[p].lchild; cd[cdlen++] ='0'; }
else if (HT[p].rchild == 0) { // 登记叶子结点的字符的编码
HC[p] = (char *)malloc((cdlen+1) * sizeof(char));
cd[cdlen] ='�'; strcpy(HC[p], cd); // 复制编码(串)
}
} else if (HT[p].weight==1) { // 向右
HT[p].weight = 2;
if (HT[p].rchild != 0) { p = HT[p].rchild; cd[cdlen++] ='1'; }
} else { // HT[p].weight==2,退回退到父结点,编码长度减1
HT[p].weight = 0; p = HT[p].parent; --cdlen;
}
}
} // HuffmanCoding


