最近在看一本 Linux 环境编程的书,加上之前工作中接触了一些关于存储的东西,便突然有兴趣整理一下 Linux 是怎么支撑文件系统的。
文件系统本是 2020 年的计划议题,去年琐事极多,一篇文章用了半年才开了一个头。最近转岗,忙于无实物表演,索性抓紧收尾。
文件的读写
我们先从文件的读写开始聊起,当我们尝试向一个文件中写入一串字符的背后,到底发生了什么事情,比如下面几行的 Python 代码:
f = open("file.txt", "w")
f.write("hello world")
f.close()
通过 strace 命令,可以很轻易的得知这行命令背后使用了哪些系统调用:
$ strace python justwrite.py -e trace=file
···
open("file.txt", O_WRONLY|O_CREAT|O_TRUNC, 0666) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=0, ...}) = 0
...
write(3, "hello world", 11) = 11
close(3) = 0
···
其中,最关键的在于 write,可以看到,通过 write 系统调用,把 “hello world” 写入到 id 为 3 的文件描述符中。
这些系统调用背后的事情我们暂且不表,我们再看下读文件时又发生了什么事情,比如:
f = open("file.txt", "r")
_ = f.readlines()
f.close()
同样,我们看下读文件使用了哪些系统调用:
$ strace python justread.py -e trace=file
...
open("file.txt", O_RDONLY) = 3
fstat(3, {st_mode=S_IFREG|0644, st_size=11, ...}) = 0
fstat(3, {st_mode=S_IFREG|0644, st_size=11, ...}) = 0
...
read(3, "hello world", 8192) = 11
read(3, "", 4096) = 0
close(3)
...
可以看到,其中最重要的是 read 系统调用,该系统调用从文件描述符为 3 的地方读取了 “hello world” 字符串。
系统调用是内核提供的 api,众所周知,操作系统托管了一切资源,一般情况下,程序只能利用系统调用来让内核替我们实现所需操作(更确切的说,是程序陷入内核完成了操作)。

VFS 与文件系统
要了解系统调用背后做了什么,需要从VFS 说起。
VFS 全称 Virtual File System,也就是虚拟文件系统,是 Linux 中 IO 操作的重要的操作接口(interface)和基础设施,可以画一张精简的 Linux IO 栈来表现 VFS 的位置:
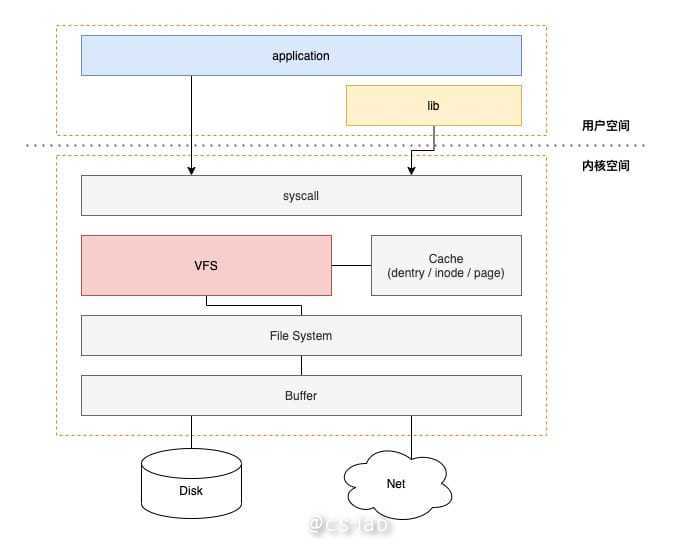
VFS 本身可以理解为是 Linux 针对文件系统约定的 Interface,Linux 为了实现这种这套接口,采用类似面向对象的设计思路(而且代码结构也像极了)。
VFS 主要抽象了四种对象类型:
- 超级块对象(super block):代表一个已安装的文件系统;
- 索引节点对象(inode):代表具体的文件;
- 目录项对象(dentry):代表一个目录项,也是文件路径的一个组成部分;
- 文件对象(file):代表进程打开的文件;
超级块
超级块是用于存储特定文件系统信息的数据结构。通常位于磁盘特定扇区中。如果说 inode 是文件的元数据的话,超级块就是文件系统的元数据。
超级块是反映了文件系统整体的元数据和控制信息。在挂载文件系统时,超级块中的内容会被读取,并在内存中构建超级块结构。
超级块的代码结构在 linux/fs.h 中:
👉 点击查看超级块数据结构
struct super_block {
struct list_head s_list; /* Keep this first */
dev_t s_dev; /* search index; _not_ kdev_t */
unsigned char s_blocksize_bits;
unsigned long s_blocksize;
loff_t s_maxbytes; /* Max file size */
struct file_system_type *s_type;
const struct super_operations *s_op;
const struct dquot_operations *dq_op;
const struct quotactl_ops *s_qcop;
const struct export_operations *s_export_op;
unsigned long s_flags;
unsigned long s_magic;
struct dentry *s_root;
struct rw_semaphore s_umount;
int s_count;
atomic_t s_active;
#ifdef CONFIG_SECURITY
void *s_security;
#endif
const struct xattr_handler **s_xattr;
struct list_head s_inodes; /* all inodes */
struct hlist_bl_head s_anon; /* anonymous dentries for (nfs) exporting */
struct list_head s_mounts; /* list of mounts; _not_ for fs use */
struct block_device *s_bdev;
struct backing_dev_info *s_bdi;
struct mtd_info *s_mtd;
struct hlist_node s_instances;
struct quota_info s_dquot; /* Diskquota specific options */
struct sb_writers s_writers;
char s_id[32]; /* Informational name */
u8 s_uuid[16]; /* UUID */
void *s_fs_info; /* Filesystem private info */
unsigned int s_max_links;
fmode_t s_mode;
/* Granularity of c/m/atime in ns.
Cannot be worse than a second */
u32 s_time_gran;
/*
* The next field is for VFS *only*. No filesystems have any business
* even looking at it. You had been warned.
*/
struct mutex s_vfs_rename_mutex; /* Kludge */
/*
* Filesystem subtype. If non-empty the filesystem type field
* in /proc/mounts will be "type.subtype"
*/
char *s_subtype;
/*
* Saved mount options for lazy filesystems using
* generic_show_options()
*/
char __rcu *s_options;
const struct dentry_operations *s_d_op; /* default d_op for dentries */
/*
* Saved pool identifier for cleancache (-1 means none)
*/
int cleancache_poolid;
struct shrinker s_shrink; /* per-sb shrinker handle */
/* Number of inodes with nlink == 0 but still referenced */
atomic_long_t s_remove_count;
/* Being remounted read-only */
int s_readonly_remount;
/* AIO completions deferred from interrupt context */
struct workqueue_struct *s_dio_done_wq;
/*
* Keep the lru lists last in the structure so they always sit on their
* own individual cachelines.
*/
struct list_lru s_dentry_lru ____cacheline_aligned_in_smp;
struct list_lru s_inode_lru ____cacheline_aligned_in_smp;
struct rcu_head rcu;
};
虽然字段有点多,但我认为可以归为几个大类:
- 设备的元数据和控制位
- 文件系统的元数据和控制位
- 超级快结构的操作函数
VFS 代码里非常有趣的就是操作函数的处理,我很惊讶于可以用 C 的进行面向对象编程。
超级块的操作函数在一个单独结构体中:
const struct super_operations *s_op;
super_operations 结构体包含了对超级块的操作方法,我认为可以视为是面向超级块的 Interface,因为这个结构并没有具体的实现,而是函数指针,不同的文件系统可以实现这些函数,来实现超级块可用:
👉 点击查看超级块操作接口
struct super_operations {
struct inode *(*alloc_inode)(struct super_block *sb);
void (*destroy_inode)(struct inode *);
void (*dirty_inode) (struct inode *, int flags);
int (*write_inode) (struct inode *, struct writeback_control *wbc);
int (*drop_inode) (struct inode *);
void (*evict_inode) (struct inode *);
void (*put_super) (struct super_block *);
int (*sync_fs)(struct super_block *sb, int wait);
int (*freeze_fs) (struct super_block *);
int (*unfreeze_fs) (struct super_block *);
int (*statfs) (struct dentry *, struct kstatfs *);
int (*remount_fs) (struct super_block *, int *, char *);
void (*umount_begin) (struct super_block *);
int (*show_options)(struct seq_file *, struct dentry *);
int (*show_devname)(struct seq_file *, struct dentry *);
int (*show_path)(struct seq_file *, struct dentry *);
int (*show_stats)(struct seq_file *, struct dentry *);
#ifdef CONFIG_QUOTA
ssize_t (*quota_read)(struct super_block *, int, char *, size_t, loff_t);
ssize_t (*quota_write)(struct super_block *, int, const char *, size_t, loff_t);
#endif
int (*bdev_try_to_free_page)(struct super_block*, struct page*, gfp_t);
long (*nr_cached_objects)(struct super_block *, int);
long (*free_cached_objects)(struct super_block *, long, int);
};
这些函数是见名知意的,所有不需要太多解释,包括了文件系统和索引节点的底层操作。
inode
inode 是比较常见的概念,inode 包含了内核在操作文件或者目录时需要的全部信息。
inode 的结构也在 linux/fs.h 中:
👉 点击查看 inode 数据结构
/*
* Keep mostly read-only and often accessed (especially for
* the RCU path lookup and 'stat' data) fields at the beginning
* of the 'struct inode'
*/
struct inode {
umode_t i_mode;
unsigned short i_opflags;
kuid_t i_uid;
kgid_t i_gid;
unsigned int i_flags;
#ifdef CONFIG_FS_POSIX_ACL
struct posix_acl *i_acl;
struct posix_acl *i_default_acl;
#endif
const struct inode_operations *i_op;
struct super_block *i_sb;
struct address_space *i_mapping;
#ifdef CONFIG_SECURITY
void *i_security;
#endif
/* Stat data, not accessed from path walking */
unsigned long i_ino;
/*
* Filesystems may only read i_nlink directly. They shall use the
* following functions for modification:
*
* (set|clear|inc|drop)_nlink
* inode_(inc|dec)_link_count
*/
union {
const unsigned int i_nlink;
unsigned int __i_nlink;
};
dev_t i_rdev;
loff_t i_size;
struct timespec i_atime;
struct timespec i_mtime;
struct timespec i_ctime;
spinlock_t i_lock; /* i_blocks, i_bytes, maybe i_size */
unsigned short i_bytes;
unsigned int i_blkbits;
blkcnt_t i_blocks;
#ifdef __NEED_I_SIZE_ORDERED
seqcount_t i_size_seqcount;
#endif
/* Misc */
unsigned long i_state;
struct mutex i_mutex;
unsigned long dirtied_when; /* jiffies of first dirtying */
struct hlist_node i_hash;
struct list_head i_wb_list; /* backing dev IO list */
struct list_head i_lru; /* inode LRU list */
struct list_head i_sb_list;
union {
struct hlist_head i_dentry;
struct rcu_head i_rcu;
};
u64 i_version;
atomic_t i_count;
atomic_t i_dio_count;
atomic_t i_writecount;
const struct file_operations *i_fop; /* former ->i_op->default_file_ops */
struct file_lock *i_flock;
struct address_space i_data;
#ifdef CONFIG_QUOTA
struct dquot *i_dquot[MAXQUOTAS];
#endif
struct list_head i_devices;
union {
struct pipe_inode_info *i_pipe;
struct block_device *i_bdev;
struct cdev *i_cdev;
};
__u32 i_generation;
#ifdef CONFIG_FSNOTIFY
__u32 i_fsnotify_mask; /* all events this inode cares about */
struct hlist_head i_fsnotify_marks;
#endif
#ifdef CONFIG_IMA
atomic_t i_readcount; /* struct files open RO */
#endif
void *i_private; /* fs or device private pointer */
};
用超级块一样,inode 也有包含操作方法的 inode_operations 结构:
👉 点击查看 inode 操作接口
struct inode_operations {
struct dentry * (*lookup) (struct inode *,struct dentry *, unsigned int);
void * (*follow_link) (struct dentry *, struct nameidata *);
int (*permission) (struct inode *, int);
struct posix_acl * (*get_acl)(struct inode *, int);
int (*readlink) (struct dentry *, char __user *,int);
void (*put_link) (struct dentry *, struct nameidata *, void *);
int (*create) (struct inode *,struct dentry *, umode_t, bool);
int (*link) (struct dentry *,struct inode *,struct dentry *);
int (*unlink) (struct inode *,struct dentry *);
int (*symlink) (struct inode *,struct dentry *,const char *);
int (*mkdir) (struct inode *,struct dentry *,umode_t);
int (*rmdir) (struct inode *,struct dentry *);
int (*mknod) (struct inode *,struct dentry *,umode_t,dev_t);
int (*rename) (struct inode *, struct dentry *,
struct inode *, struct dentry *);
int (*setattr) (struct dentry *, struct iattr *);
int (*getattr) (struct vfsmount *mnt, struct dentry *, struct kstat *);
int (*setxattr) (struct dentry *, const char *,const void *,size_t,int);
ssize_t (*getxattr) (struct dentry *, const char *, void *, size_t);
ssize_t (*listxattr) (struct dentry *, char *, size_t);
int (*removexattr) (struct dentry *, const char *);
int (*fiemap)(struct inode *, struct fiemap_extent_info *, u64 start,
u64 len);
int (*update_time)(struct inode *, struct timespec *, int);
int (*atomic_open)(struct inode *, struct dentry *,
struct file *, unsigned open_flag,
umode_t create_mode, int *opened);
int (*tmpfile) (struct inode *, struct dentry *, umode_t);
} ____cacheline_aligned;
inode_operations 结构包含了文件相关的操作接口,包括了:
- 文件、目录的创建删除重命名
- 软硬连接管理
- 权限相关的管理
- 拓展参数的管理
一样的,inode_operations 结构并没有具体的实现,而只是通过函数指针作为 Interface 存在,具体的操作系统将实现结构中的函数。
目录项
VFS 把目录当做一种特殊的文件,所以对于一个文件路径,比如:/dir1/file1 中,/、dri1 和 file1 都属于目录项。
上述路径中的每个组成部分,无论是目录、还是文件都会有一个目录项结构表示,这个样子,在 VFS 执行目录操作,比如路径名查找等,都会变得比较方便。
目录项的数据结构在 linux/dcache.h 中:
👉 点击查看目录项数据结构
```c /* * Try to keep struct dentry aligned on 64 byte cachelines (this will * give reasonable cacheline footprint with larger lines without the * large memory footprint increase). */ #ifdef CONFIG_64BIT # define DNAME_INLINE_LEN 32 /* 192 bytes */ #else # ifdef CONFIG_SMP # define DNAME_INLINE_LEN 36 /* 128 bytes */ # else # define DNAME_INLINE_LEN 40 /* 128 bytes */ # endif #endif#define d_lock d_lockref.lock
struct dentry {
/* RCU lookup touched fields /
unsigned int d_flags; / protected by d_lock /
seqcount_t d_seq; / per dentry seqlock /
struct hlist_bl_node d_hash; / lookup hash list */
struct dentry d_parent; / parent directory */
struct qstr d_name;
struct inode d_inode; / Where the name belongs to - NULL is
* negative /
unsigned char d_iname[DNAME_INLINE_LEN]; / small names */
/* Ref lookup also touches following */
struct lockref d_lockref; /* per-dentry lock and refcount */
const struct dentry_operations *d_op;
struct super_block *d_sb; /* The root of the dentry tree */
unsigned long d_time; /* used by d_revalidate */
void *d_fsdata; /* fs-specific data */
struct list_head d_lru; /* LRU list */
/*
* d_child and d_rcu can share memory
*/
union {
struct list_head d_child; /* child of parent list */
struct rcu_head d_rcu;
} d_u;
struct list_head d_subdirs; /* our children */
struct hlist_node d_alias; /* inode alias list */
};
</details>
</br>
和前面的结构不同,目录项的字段比较简单,而且并没有磁盘相关的属性。这是因为目录项是在使用时创建的,VFS 会根据路径字符串进行解析创建。也因此可以看出,目录项并不是保存在磁盘中的数据,而是内存中起到 cache 作用的结构。
目录项的缓存可以通过 slabinfo 查看:
```bash
$ slabinfo | awk 'NR==1 || $1=="dentry" {print}'
Name Objects Objsize Space Slabs/Part/Cpu O/S O %Fr %Ef Flg
dentry 608813 192 139.5M 33924/16606/142 21 0 48 83 a
目录项既然是文件系统在内存中的缓存,因此目录项的管理就和普通 cache 的管理非常接近。比如判断是否有效,对缓存结构的释放等。这些操作便包含在目录项的操作结构中:
👉 点击查看目录项操作接口
```c struct dentry_operations { int (*d_revalidate)(struct dentry *, unsigned int); int (*d_weak_revalidate)(struct dentry *, unsigned int); int (*d_hash)(const struct dentry *, struct qstr *); int (*d_compare)(const struct dentry *, const struct dentry *, unsigned int, const char *, const struct qstr *); int (*d_delete)(const struct dentry *); void (*d_release)(struct dentry *); void (*d_prune)(struct dentry *); void (*d_iput)(struct dentry *, struct inode *); char *(*d_dname)(struct dentry *, char *, int); struct vfsmount *(*d_automount)(struct path *); int (*d_manage)(struct dentry *, bool); } ____cacheline_aligned; ```文件
文件结构用于表示进程已打开的文件,是当前文件的内存的数据结构。这个结构在open 系统调用时创建,在 close 系统调用时释放,所有对文件的操作,都是围绕这个结构展开的。
👉 点击查看文件结构
```c struct file { union { struct llist_node fu_llist; struct rcu_head fu_rcuhead; } f_u; struct path f_path; #define f_dentry f_path.dentry struct inode *f_inode; /* cached value */ const struct file_operations *f_op;/*
* Protects f_ep_links, f_flags, f_pos vs i_size in lseek SEEK_CUR.
* Must not be taken from IRQ context.
*/
spinlock_t f_lock;
atomic_long_t f_count;
unsigned int f_flags;
fmode_t f_mode;
loff_t f_pos;
struct fown_struct f_owner;
const struct cred *f_cred;
struct file_ra_state f_ra;
u64 f_version;
#ifdef CONFIG_SECURITY
void f_security;
#endif
/ needed for tty driver, and maybe others */
void *private_data;
#ifdef CONFIG_EPOLL
/* Used by fs/eventpoll.c to link all the hooks to this file /
struct list_head f_ep_links;
struct list_head f_tfile_llink;
#endif / #ifdef CONFIG_EPOLL */
struct address_space *f_mapping;
#ifdef CONFIG_DEBUG_WRITECOUNT
unsigned long f_mnt_write_state;
#endif
};
</details>
</br>
对于一个文件结构来说,用来表示一个已经打开的文件,但是应该知道,当程序打开一个文件时,会拿到一个文件描述符,文件描述符和文件还是有差异的,这个后面会提到。可以看到,文件结构中有一个名为 `f_count` 的引用计数的字段,当引用计数清零时,会调用文件操作结构中的 `release` 方法,这个方法会产生什么效果由文件系统的实现决定。
对于文件的操作结构,也就是 `file_operations`,操作函数名和系统调用/库函数名称基本保持一致,不做赘述。
<details>
<summary>👉 点击查看文件操作接口</summary>
```c
struct file_operations {
struct module *owner;
loff_t (*llseek) (struct file *, loff_t, int);
ssize_t (*read) (struct file *, char __user *, size_t, loff_t *);
ssize_t (*write) (struct file *, const char __user *, size_t, loff_t *);
ssize_t (*aio_read) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
ssize_t (*aio_write) (struct kiocb *, const struct iovec *, unsigned long, loff_t);
int (*iterate) (struct file *, struct dir_context *);
unsigned int (*poll) (struct file *, struct poll_table_struct *);
long (*unlocked_ioctl) (struct file *, unsigned int, unsigned long);
long (*compat_ioctl) (struct file *, unsigned int, unsigned long);
int (*mmap) (struct file *, struct vm_area_struct *);
int (*open) (struct inode *, struct file *);
int (*flush) (struct file *, fl_owner_t id);
int (*release) (struct inode *, struct file *);
int (*fsync) (struct file *, loff_t, loff_t, int datasync);
int (*aio_fsync) (struct kiocb *, int datasync);
int (*fasync) (int, struct file *, int);
int (*lock) (struct file *, int, struct file_lock *);
ssize_t (*sendpage) (struct file *, struct page *, int, size_t, loff_t *, int);
unsigned long (*get_unmapped_area)(struct file *, unsigned long, unsigned long, unsigned long, unsigned long);
int (*check_flags)(int);
int (*flock) (struct file *, int, struct file_lock *);
ssize_t (*splice_write)(struct pipe_inode_info *, struct file *, loff_t *, size_t, unsigned int);
ssize_t (*splice_read)(struct file *, loff_t *, struct pipe_inode_info *, size_t, unsigned int);
int (*setlease)(struct file *, long, struct file_lock **);
long (*fallocate)(struct file *file, int mode, loff_t offset,
loff_t len);
int (*show_fdinfo)(struct seq_file *m, struct file *f);
};
运行态相关的数据结构
上面梳理了 VFS 的四个结构以及相关的操作,但是这四个结构只能说提供了一套接口定义,或者说给了文件系统提供了一个对接标准,是一个静态的概念。
但要用户能够使用和感知到一个文件系统,需要 mount 到当前目录树中来,以及需要程序去 Open 文件系统中的文件。这些操作,需要一些额外的数据结构。
内核还使用了一些数据结构来管理文件系统以及相关数据,比如使用 file_system_type 用来描述特定的文件系统类型:
👉 点击查看 `file_system_type` 数据结构
struct file_system_type {
const char *name;
int fs_flags;
#define FS_REQUIRES_DEV 1
#define FS_BINARY_MOUNTDATA 2
#define FS_HAS_SUBTYPE 4
#define FS_USERNS_MOUNT 8 /* Can be mounted by userns root */
#define FS_USERNS_DEV_MOUNT 16 /* A userns mount does not imply MNT_NODEV */
#define FS_RENAME_DOES_D_MOVE 32768 /* FS will handle d_move() during rename() internally. */
struct dentry *(*mount) (struct file_system_type *, int,
const char *, void *);
void (*kill_sb) (struct super_block *);
struct module *owner;
struct file_system_type * next;
struct hlist_head fs_supers;
struct lock_class_key s_lock_key;
struct lock_class_key s_umount_key;
struct lock_class_key s_vfs_rename_key;
struct lock_class_key s_writers_key[SB_FREEZE_LEVELS];
struct lock_class_key i_lock_key;
struct lock_class_key i_mutex_key;
struct lock_class_key i_mutex_dir_key;
};
每个安装到系统的文件系统,在完成挂载之前,都只是一个 file_system_type 对象,里面包含了超级块的挂载、卸载的方法用以实现 mount。
而 mount 操作不仅会完成挂载,还会创建一个 vfsmount 结构,以代表一个挂载点。vfsmount 的代码在 linux/mount.h 中:
👉 点击查看 `vfsmount` 数据结构
struct vfsmount {
struct dentry *mnt_root; /* root of the mounted tree */
struct super_block *mnt_sb; /* pointer to superblock */
int mnt_flags;
};
文件描述符
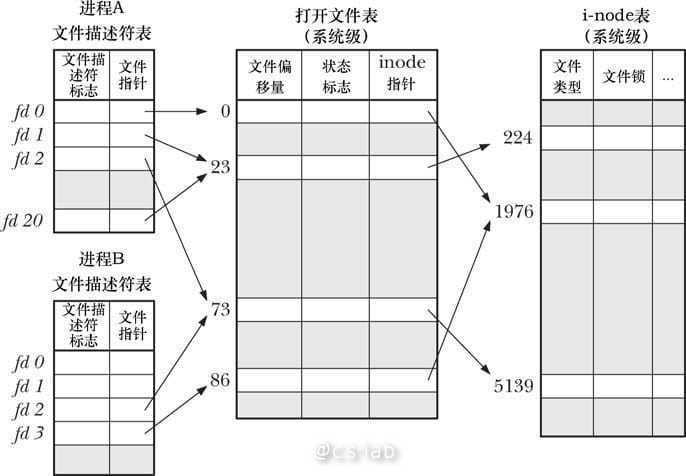
在系统中,每个进程都有自己的一组「打开的文件」,每个程序的每个文件有不同的文件描述符和读写偏移量。因此,还有几个与之相关的数据结构和上面提到的 VFS 的数据结构紧密相关。
这里讲下和文件描述符有关的 files_struct,其与前面提到的 file 名字比较迷惑,两者最大的不同在于后者是用于维护的系统所有打开的文件,而前者维护的是当前进程打开的所有文件,前者最后会指向后者。
files_struct 的结构位于 linux/fdtable.h 中:
👉 点击查看 `files_struct` 结构
/*
* Open file table structure
*/
struct files_struct {
/*
* read mostly part
*/
atomic_t count;
struct fdtable __rcu *fdt;
struct fdtable fdtab;
/*
* written part on a separate cache line in SMP
*/
spinlock_t file_lock ____cacheline_aligned_in_smp;
int next_fd;
unsigned long close_on_exec_init[1];
unsigned long open_fds_init[1];
struct file __rcu * fd_array[NR_OPEN_DEFAULT];
};
fd_array 数组指针便是指向该进程打开的所有文件,进程通过该字段找到对应的 file,从而找到对应的 inode。
文件系统
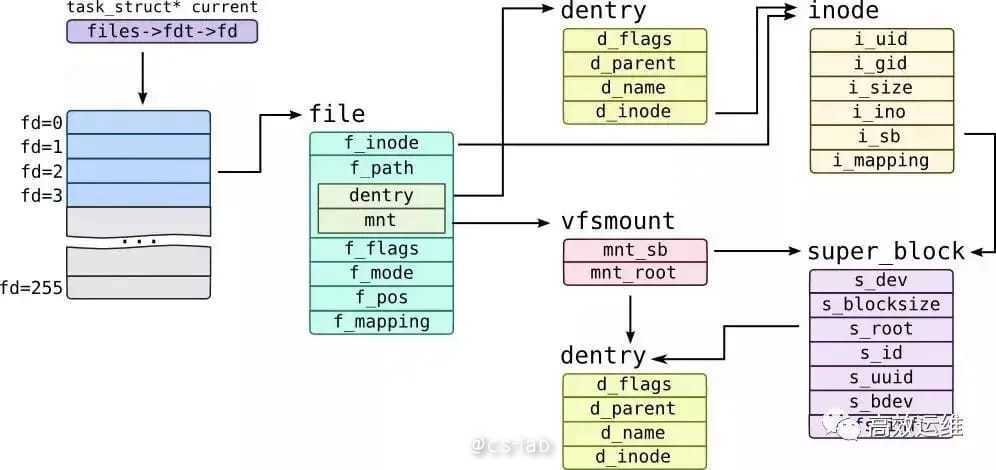
通过梳理 Linux 内核中的数据结构,可以基本摸清从进程打开文件,到 VFS 处理的过程中数据结构直接的关系,因为这些结构采用了「围绕数据的面向对象的编程方式」,结构本身就带着「方法」,所有也基本可以梳理理解 IO 请求的执行流程。如下图:
最后,再通过介绍两个非常典型的文件系统,来讲讲文件系统是如何配合 VFS 工作的。
传统的文件系统:ext2
ext2 曾是一款优秀的文件系统,是Linux 上使用最为广泛的文件系统,也是原始 Linux 文件系统 ext 的继任者。虽然 ext2 目前已经不会使用,但是因为其设计的简单,很适合用来介绍文件系统是如何工作的。
正如前面提到的,ext2 文件系统由以下几部分组成。
引导块:总是作为文件系统的首块。引导块不为文件系统所用,只是包含用来引导操作系统的信息。操作系统只需一个引导块,但所有文件系统都设有引导块,绝大多数都未使用。
超级块:紧随引导块之后的一个独立块,包含与文件系统有关的参数信息,其中包括:
- inode 表容量;
- 文件系统中逻辑块的大小;
- 以逻辑块计,文件系统的大小;
inode 表:文件系统中的每个文件或目录在 inode 表中都对应着唯一一条记录。这条记录登记了关乎文件的各种信息,比如:
- 文件类型(比如,常规文件、目录、符号链接,以及字符设备等)
- 文件属主(亦称用户 ID 或 UID)
- 文件属组(亦称为组 ID 或 GID)
- 3 类用户的访问权限:属主、属组以及其他用户
- 3 个时间戳:最后访问时间、最后修改时间 、文件状态的最后改变时间
- 指向文件的硬链接数量
- 文件的大小,以字节为单位
- 实际分配给文件的块数量
- 指向文件数据块的指针
数据块:文件系统的大部分空间都用于存放数据,以构成驻留于文件系统之上的文件和目录。
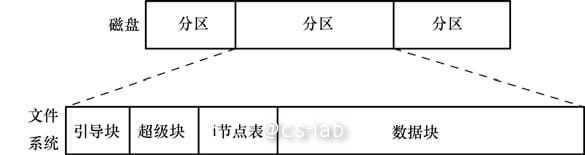
ext2 文件系统在存储文件时,数据块不一定连续,甚至不一定按顺序存放。 为了定位文件数据块, 内核在 inode 内维护有一组指针。
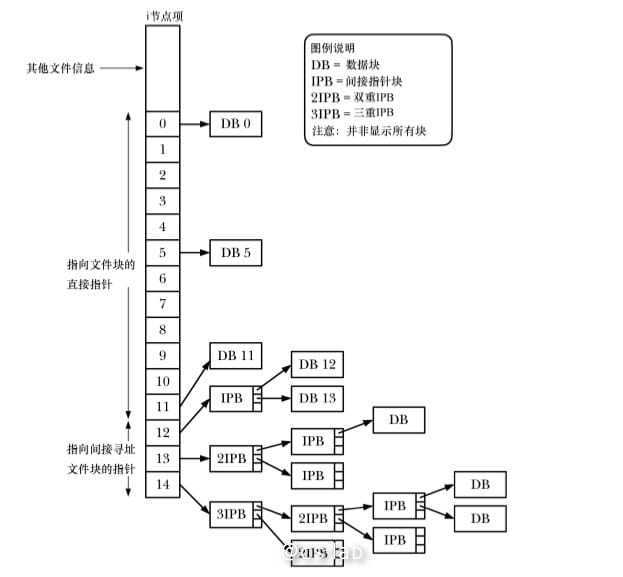
一个 inode 结构包含了 15 个指针(0-14),其中前 11 个指针用来指向数据块,这样在小文件场景下可以直接引用,后面的指针指向间接指针块,以指向后续的数据块。
因此也可以看出,对于大小为 4096 字节的块而言,理论上,单文件最大约等于 1024×1024×1024×4096 字节,或 4TB(4096 GB)。
日志文件系统:XFS
第二个例子可以看下常见的现代文件系统 xfs,xfs 是 Silicon Graphics 为他们的 IRIX 操作系统而开发,在大文件处理和传输性能上有不错的表现。
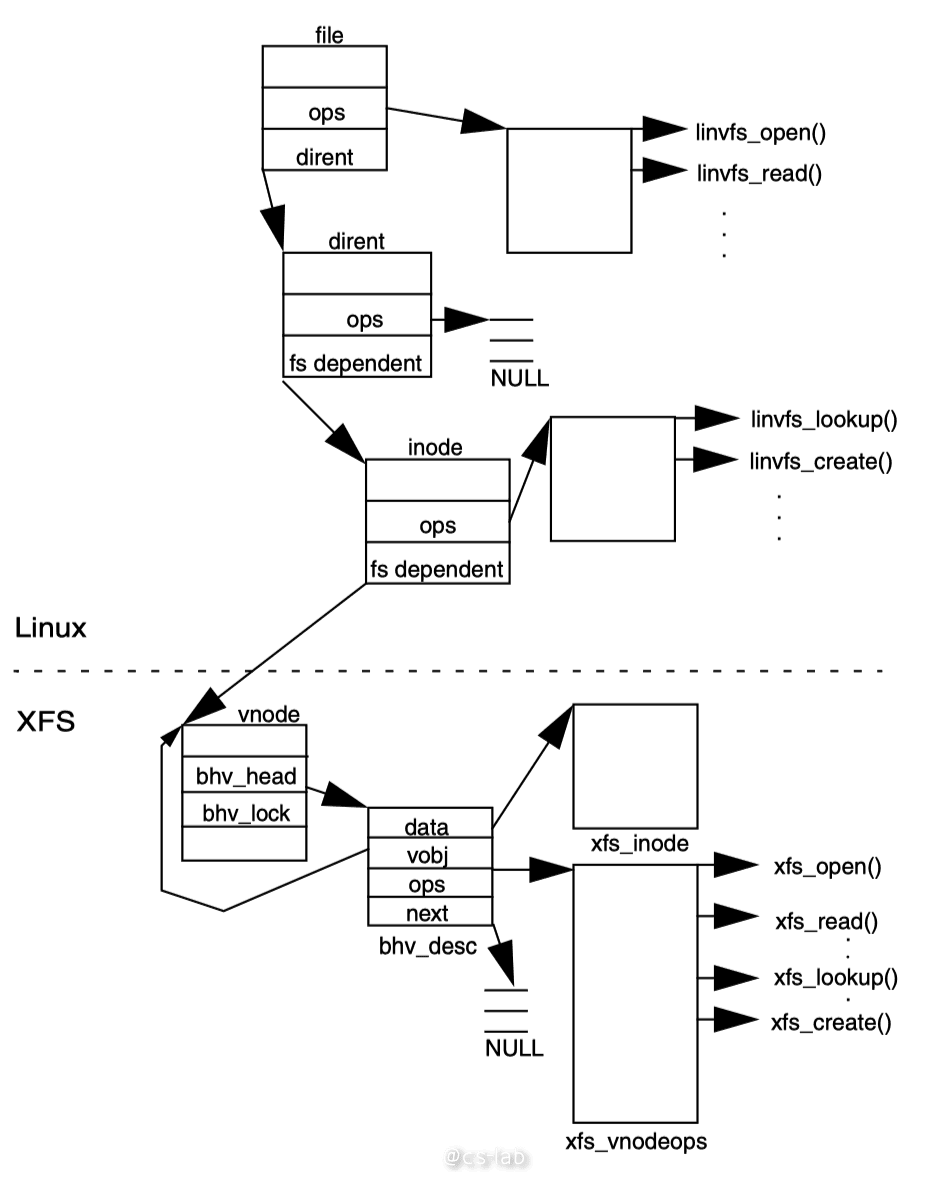
这篇文章重点并不是为了讲 xfs 的工作原理,而是从 Linux 视角看待 xfs。xfs 不像 ext 系专为 Linux 定制的,所以在文件系统处理上并没有按照 VFS 设计。
在 VFS 中, 文件的操作分为了两层: file(文件读写等), inode(文件创建删除等),而在 xfs 中只有一层 vnode 来提供所有操作。所以在移植 XFS 到 Linux 过程中,为了适配 VFS 引入了一个转换中间层 linvfs,将对 file 和 inode 的操作映射到 vnode 中。
最后
本文梳理了 VFS 核心数据结构和之间的关系,但是了解 VFS 有什么用的。我认为是两个方面的作用。
第一是理解 Linux 文件系统是怎么工作的,这对以理解一次 IO 发生了什么很有帮助。
第二是有助于理解 Linux 中的 IO 缓存,VFS 和很多缓存息息相关,包括页缓存,目录缓存,inode 缓存:
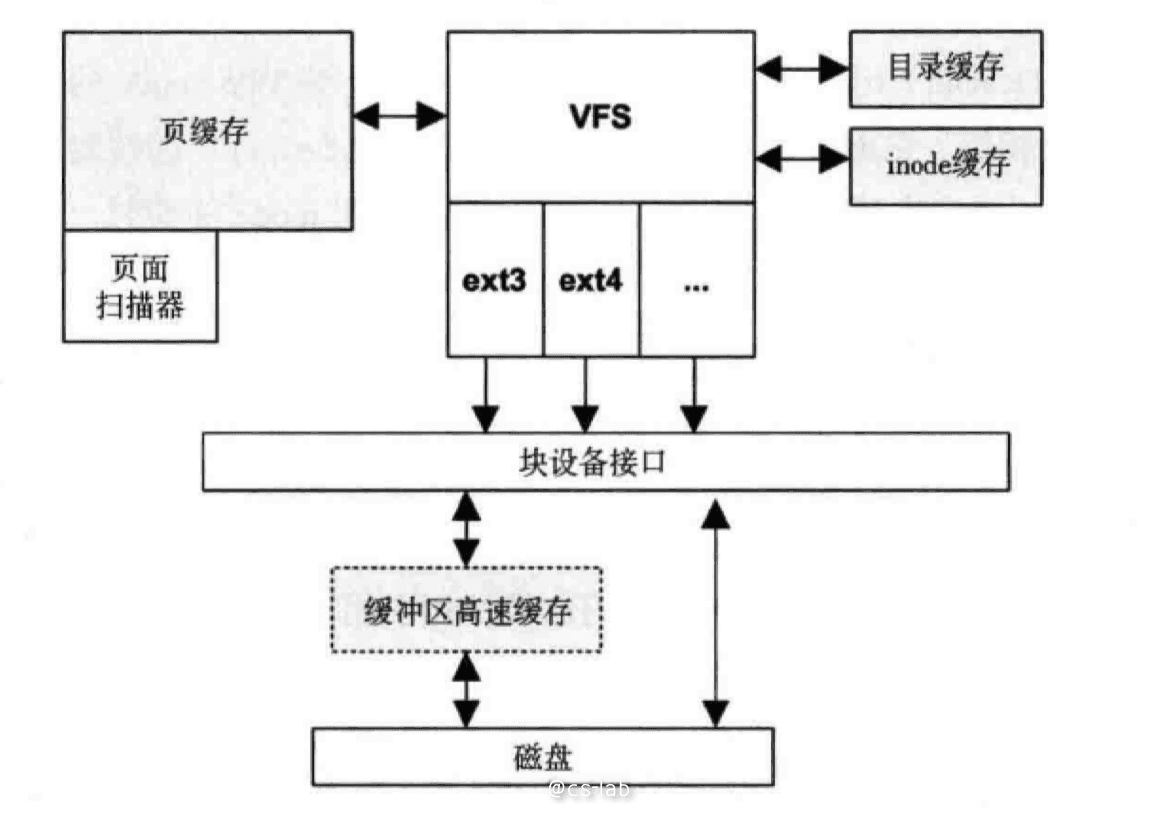
除了 inode 和目录项在内存的结构起到缓存作用外,比如页缓存用于缓存最近读写的文件数据块,其中 file.address_space 字段便是用于管理页缓存。
参考
- 《Linux/UNIX 系统编程手册》
- 《Linux 内核设计与实现》
- 《Porting the SGI XFS File System to Linux》


