
前一段时间在死磕 ElasticSearch,本着偷师学艺的目的来读一下 ElasticSearch Operator 代码,学习一下 Operator 管理 ElasticSearch 集群的方式,优美下使用 ElasticSearch 的姿势。最后发现也没有多么神秘,Operator 目前只是专注于 ES 集群 Lifecycle 的管理,实现的方式也比较简单。
Github:https://github.com/elastic/cloud-on-k8s
目前的最新版本:v1.1
ElasticSearch Operator
目前 ElasticSearch Operator 的核心 features:
- Elasticsearch, Kibana and APM Server deployments
- TLS Certificates management
- Safe Elasticsearch cluster configuration & topology changes
- Persistent volumes usage
- Custom node configuration and attributes
- Secure settings keystore updates
安装
安装 ElasticSearch Operator 十分简单,基于 all in one yaml,快速拉起 Operator 所有组件,并注册 CRD。
kubectl apply -f https://download.elastic.co/downloads/eck/1.1.2/all-in-one.yaml
CRD
Operator 主要注册了三个 CRD:APM、ElasticSearch、Kibana:
k get crd | grep elastic
apmservers.apm.k8s.elastic.co 2020-05-10T08:02:15Z
elasticsearches.elasticsearch.k8s.elastic.co 2020-05-10T08:02:15Z
kibanas.kibana.k8s.elastic.co 2020-05-10T08:02:15Z
ElasticSearch Cluster Demo
一个完整的 ElasticSearch Cluster Yaml,包括创建 ES 集群,本地 PV 和 Kibana。
👉 点击查看 ElasticSearch CR Yaml
apiVersion: v1
kind: Namespace
metadata:
creationTimestamp: null
name: elastic-stack
---
apiVersion: elasticsearch.k8s.elastic.co/v1
kind: Elasticsearch
metadata:
name: elasticsearch
namespace: elastic-stack
spec:
version: 7.6.2
nodeSets:
- name: default
count: 1
config:
node.master: true
node.data: true
node.ingest: true
node.store.allow_mmap: false
---
apiVersion: kibana.k8s.elastic.co/v1
kind: Kibana
metadata:
name: kibana
namespace: elastic-stack
spec:
version: 7.6.2
count: 1
elasticsearchRef:
name: elasticsearch
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: es-db-0
labels:
type: local
spec:
volumeMode: Filesystem
persistentVolumeReclaimPolicy: Retain
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/data/elastic/db-0"
---
apiVersion: v1
kind: PersistentVolume
metadata:
name: es-db-1
labels:
type: local
spec:
volumeMode: Filesystem
persistentVolumeReclaimPolicy: Retain
capacity:
storage: 5Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/data/elastic/db-1"
Operator 对 ElasticSearch 的管理
和众多基于声明式 Api 实现的 Operator 一样, Elastic Operator 的重点也是围绕着 Reconcile 函数展开的。
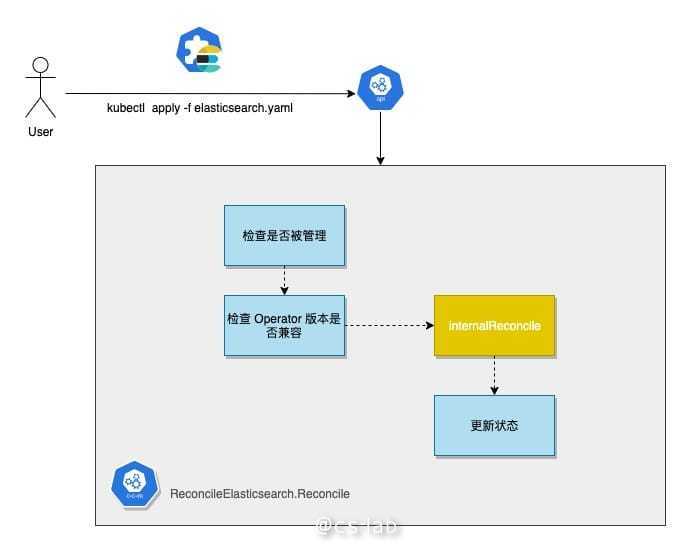
Reconcile 函数完成 ES 集群整个生命周期的管理,我比较感兴趣并简单讲解下下述功能的实现:
- 配置初始化和管理
- 集群节点的 scale up 和 scale down
- 有状态应用的生命周期管理
创建集群
Reconcile 函数在收到 ElasticSearch CR 之后,会首先对 CR 进行若干合法性检查,首先是检查 Operator 对 CR 的控制权,包括是否有暂停标记,是否符合 Operator 的版本限制。通过之后,便会调用 internalReconcile 进一步处理。
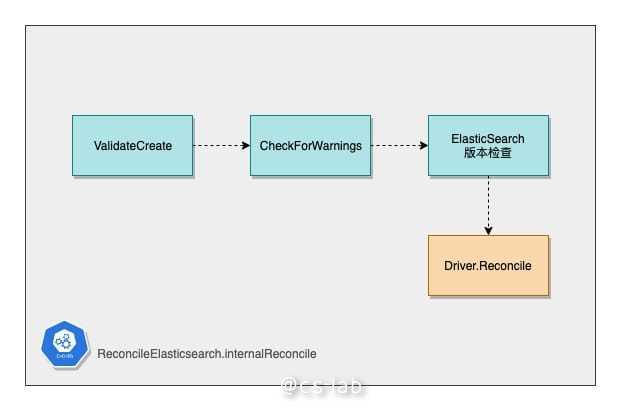
internalReconcile 函数便是开始侧重于对 ElasticSearch CR 的业务合法性进行检查,通过定义若干 validation,对即将进行后续操作的 CR 进行参数合法性检查。
type validation func(*Elasticsearch) field.ErrorList
// validations are the validation funcs that apply to creates or updates
var validations = []validation{
noUnknownFields,
validName,
hasMaster,
supportedVersion,
validSanIP,
}
type updateValidation func(*Elasticsearch, *Elasticsearch) field.ErrorList
// updateValidations are the validation funcs that only apply to updates
var updateValidations = []updateValidation{
noDowngrades,
validUpgradePath,
pvcModification,
}
当 ES CR 的合法性检查通过之后,便开始了真正的 Reconcile 逻辑。
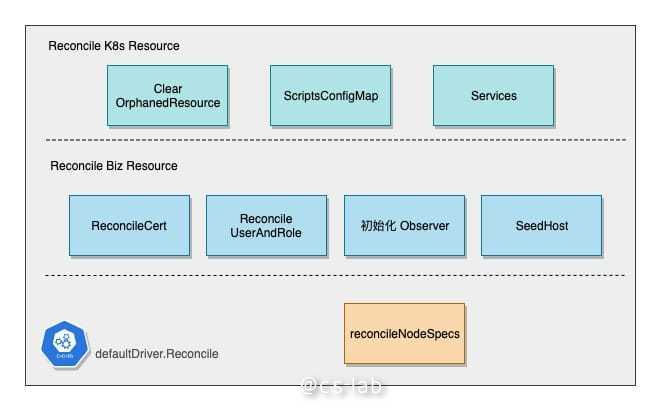
我把后续 Driver 的操作分为三个部分:
- Reconcile Kubernetes Resource
- Reconcile ElasticSearch Cluster Business Config & Resource
- Reconcile Node Spec
首先是清理不匹配的 Kubernetes 资源,然后检查并创建 Script ConfigMap,以及两个 Service。
ElasticSearch 会用到两个 Service,便是在这一步进行创建和矫正的:
- TransportService:headless Service,es 集群 zen discovery 使用
- ExternalService:对 es data 节点的 L4 负载均衡
$ k -n elastic-stack get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
elasticsearch-es-http ClusterIP 10.96.42.27 <none> 9200/TCP 103d
elasticsearch-es-transport ClusterIP None <none> 9300/TCP 103d
Script ConfigMap 是一个让我比较惊奇的操作,因为 ES Cluster 是有状态的,因此有部分启动初始化和停机收尾的工作,Operator 会生成相关的脚本,并通过 ConfigMap 挂载到 Pod 中,并在 Pod 的 Lifecycle hook 中进行执行,Operator 会渲染三个脚本,其命名也是自解释的:
readiness-probe-script.shpre-stop-hook-script.shprepare-fs.sh
在对 K8s 的资源进行创建之后,便开始处理 ES 集群运行需要的其他依赖,比如 CA 和证书,用户和权限的配置文件,种子主机的配置等,这些都会创建好相应的 ConfigMap 或 Secret,并等待启动时注入到 Pod 中。
除此之外, Operator 还在这里初始化了 Observer,这是一个定期轮询 ES 状态的组件,并缓存了当前 Cluster 的最新状态,也可以变相的实现 Cluster Stat Watch,后面会详细说明。
当这些启动依赖准备完成,之后,剩下的就是创建具体的资源尝试把 Pod 拉起来了。
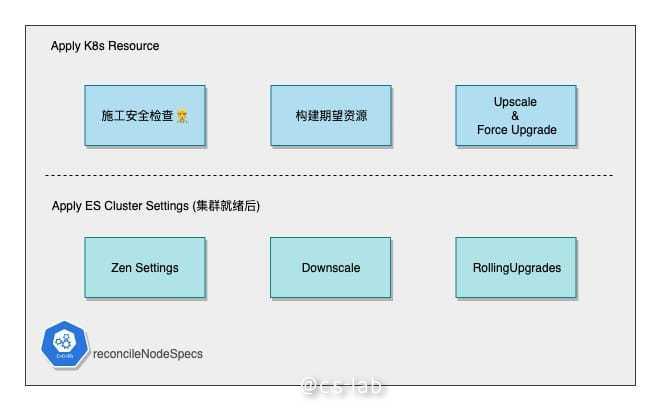
正式创建和矫正 ES 资源是分两个阶段进行的,分水岭是 ES Cluster 是否就绪(通过 Service 是否可以访问 ES 集群)。
第一个阶段首先进行施工安全检查:
- 本地的资源对象缓存是否符合期望
- StatefulSet 以及 Pod 是否正常(Generation 和 Pod 的数目)
然后根据 CR 构建期望的 StatefulSet & Service 资源,后续的操作便是尝试逼近此处构建的终态。
对于终态描述的资源,Operator 会进行限流创建,此处做的比较复杂,但基本流程就是逐步修改 StatefulSet 的副本数,直到达到期望。
如果存在旧的 Pod 需要更新,便会通过简单有效的 delete po 将 Pod 删掉,进行强制更新。到此第一阶段就进行完了,而相关的 K8s 资源也基本创建完成。
但是 ES 集群的创建工作还未完成,当 Operator 可以通过 http client 访问到 ES 集群后,进行第二阶段的创建工作。
首先是基于当前的 Master 数调整 Zen Discovery 配置,以及 Voting 相关配置。
后面会再进行 scale down 以及 rolling upgrade 的相关操作,不过对于集群的创建来说,到这里已经完成了。
Rolling Upgrades
因为 ElasticSearch 是一个类似数据库的有状态应用,因此我对 ES 集群的升级和后续生命周期维护比较感兴趣,在 Reconcile Node Specs 中,Scale Up 做的比较简单,得益于 ES 通过 Zen 实现了基于域名的自我发现,因此新 Pod 被加入到 Endpoints 后便会自动加入集群中。
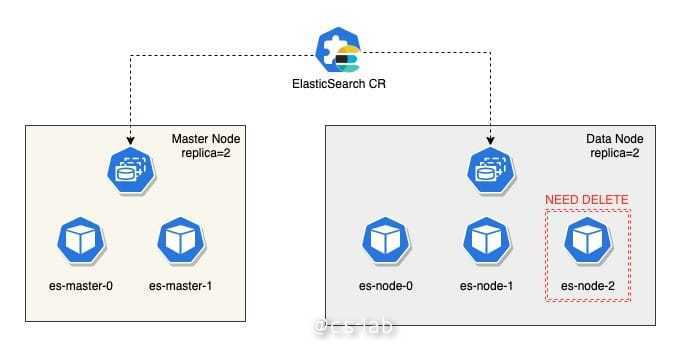
但是因为每个节点都维护了部分 shard,所以节点下线或者节点升级,都会涉及到 shard 数据的处理问题。
👉 点击查看处理 Scale Down 相关逻辑
func HandleDownscale(
downscaleCtx downscaleContext,
expectedStatefulSets sset.StatefulSetList,
actualStatefulSets sset.StatefulSetList,
) *reconciler.Results {
results := &reconciler.Results{}
// make sure we only downscale nodes we're allowed to
downscaleState, err := newDownscaleState(downscaleCtx.k8sClient, downscaleCtx.es)
if err != nil {
return results.WithError(err)
}
// compute the list of StatefulSet downscales and deletions to perform
downscales, deletions := calculateDownscales(*downscaleState, expectedStatefulSets, actualStatefulSets)
// remove actual StatefulSets that should not exist anymore (already downscaled to 0 in the past)
// this is safe thanks to expectations: we're sure 0 actual replicas means 0 corresponding pods exist
if err := deleteStatefulSets(deletions, downscaleCtx.k8sClient, downscaleCtx.es); err != nil {
return results.WithError(err)
}
// migrate data away from nodes that should be removed
// if leavingNodes is empty, it clears any existing settings
leavingNodes := leavingNodeNames(downscales)
if err := migration.MigrateData(downscaleCtx.parentCtx, downscaleCtx.es, downscaleCtx.esClient, leavingNodes); err != nil {
return results.WithError(err)
}
for _, downscale := range downscales {
// attempt the StatefulSet downscale (may or may not remove nodes)
requeue, err := attemptDownscale(downscaleCtx, downscale, actualStatefulSets)
if err != nil {
return results.WithError(err)
}
if requeue {
// retry downscaling this statefulset later
results.WithResult(defaultRequeue)
}
}
return results
}
Scale Down 或者说下线节点的逻辑并不复杂,依然是计算期望与当前的差异。确定 StatefuleSet 应该把 replica 调整到什么数量。
如果 replica 为零,直接将 StatefulSet 删除,如果不为零,则开始了节点下线的操作。

下线是分两步,首先是计算哪些 Node 需要下线,然后通过 setting api,触发 shard 的重分配,把即将下线的 Node 排除在外。
最后,会检查 Node 中的 shard 是否被清空,如果没有,则会 requeue 等待下次处理,如果已经被清空则开始执行真正的更新 replica 操作。
在 Rolling Upgrades 时也是类似的操作,首先是计算新旧资源,并把旧的资源清除,在清除完成后,通过 ES Client 打开 ShardsAllocation,以确保 Cluster 中 Shard 的恢复。
Watch
在上文中提到了 ElasticSearch Operator 内置了一个 Observer 模块,来通过轮询的方式实现了对 ES 集群状态的 Watch。

ObserverManager 管理了若干个 Observer,每个 ES Cluster 都有一个 Observer 单例,并且定时去轮询 ES Cluster 的状态。如果状态发生了改变,便会触发注册的 listeners。
目前实现的 listener 只有一个,就是 healthChangeListener,这个 Listener 的工作内容非常简单,就是发现了状态变化,而且是集群 Health 发生了改变,便会发送一个 event 到 chan 中。
// healthChangeListener returns an OnObservation listener that feeds a generic
// event when a cluster's observed health has changed.
func healthChangeListener(reconciliation chan event.GenericEvent) OnObservation {
return func(cluster types.NamespacedName, previous State, new State) {
// no-op if health hasn't change
if !hasHealthChanged(previous, new) {
return
}
// trigger a reconciliation event for that cluster
evt := event.GenericEvent{
Meta: &metav1.ObjectMeta{
Namespace: cluster.Namespace,
Name: cluster.Name,
},
}
reconciliation <- evt
}
}
而这个 chan 和 contoller-runtime 提供的 Watch 能力有关,当事件被发布时,便会触发 Operator 开始的 Reconcile 流程。从而实现了发现业务状态的变化,会把该 CR 继续交付给 Operator 来进行校正。
// Controller implements a Kubernetes API. A Controller manages a work queue fed reconcile.Requests
// from source.Sources. Work is performed through the reconcile.Reconciler for each enqueued item.
// Work typically is reads and writes Kubernetes objects to make the system state match the state specified
// in the object Spec.
type Controller interface {
// Reconciler is called to reconcile an object by Namespace/Name
reconcile.Reconciler
// Watch takes events provided by a Source and uses the EventHandler to
// enqueue reconcile.Requests in response to the events.
//
// Watch may be provided one or more Predicates to filter events before
// they are given to the EventHandler. Events will be passed to the
// EventHandler if all provided Predicates evaluate to true.
Watch(src source.Source, eventhandler handler.EventHandler, predicates ...predicate.Predicate) error
// Start starts the controller. Start blocks until stop is closed or a
// controller has an error starting.
Start(stop <-chan struct{}) error
}
Operator 对 License 的管理
ElasticSearch 作为一个有商业授权的软件,Operator 中的 License 管理真的是让我对 App On K8s 的 License 管理又多了一种认识。
去年年底的时候,在参与一个基于 K8s 的系统的开发,当时我就比较困惑 K8s 这种 “云操作系统” 上的软件应该怎么授权管理,而 ES Operator 就给了一个比较具体的解决方案。
首先是 License 的结构,Operator 定义了两种,一个是提供给 ES Cluster 使用的 License,这个 Model 最终会被 apply 到 ES 集群中:
// License models the Elasticsearch license applied to a cluster. Signature will be empty on reads. IssueDate, ExpiryTime and Status can be empty on writes.
type License struct {
Status string `json:"status,omitempty"`
UID string `json:"uid"`
Type string `json:"type"`
IssueDate *time.Time `json:"issue_date,omitempty"`
IssueDateInMillis int64 `json:"issue_date_in_millis"`
ExpiryDate *time.Time `json:"expiry_date,omitempty"`
ExpiryDateInMillis int64 `json:"expiry_date_in_millis"`
MaxNodes int `json:"max_nodes,omitempty"`
MaxResourceUnits int `json:"max_resource_units,omitempty"`
IssuedTo string `json:"issued_to"`
Issuer string `json:"issuer"`
StartDateInMillis int64 `json:"start_date_in_millis"`
Signature string `json:"signature,omitempty"`
}
另一个就是交由 Operator 进行管理使用的 License 结构,Operator 会基于这几个 Model 进行校验和逻辑处理:
type ElasticsearchLicense struct {
License client.License `json:"license"`
}
type EnterpriseLicense struct {
License LicenseSpec `json:"license"`
}
type LicenseSpec struct {
Status string `json:"status,omitempty"`
UID string `json:"uid"`
Type OperatorLicenseType `json:"type"`
IssueDate *time.Time `json:"issue_date,omitempty"`
IssueDateInMillis int64 `json:"issue_date_in_millis"`
ExpiryDate *time.Time `json:"expiry_date,omitempty"`
ExpiryDateInMillis int64 `json:"expiry_date_in_millis"`
MaxInstances int `json:"max_instances,omitempty"`
MaxResourceUnits int `json:"max_resource_units,omitempty"`
IssuedTo string `json:"issued_to"`
Issuer string `json:"issuer"`
StartDateInMillis int64 `json:"start_date_in_millis"`
Signature string `json:"signature,omitempty"`
ClusterLicenses []ElasticsearchLicense `json:"cluster_licenses"`
Version int // not marshalled but part of the signature
}
License 的校验和使用
Operator 的 License 做的简单但够用(可能法务足够给力),是由 License Controller 和 ElasticSearch Controller 共同配合完成。
License Controller 会对 ElasticSearch CR 进行 Watch,接收到新的事件之后,会在 Operator 同 Namespace 下寻找包含了 License 的 Secret,并根据过期时间、ES 版本等信息寻找可用的 License。
然后使用编译阶段注入的公钥,对 License 进行签名检查,如果通过便会为该 ElasticSearch CR 创建包含 License 的特定 Secret(Cluster Name 加固定后缀)。

ElasticSearch Controller 是管理 ElasticSearch 生命周期的主要 Controller,在接收到 CR 的事件后,会判断该 ES Cluster 是否已经就绪(可以通过 Service 发生 Http 请求)。如果已经就绪,就根据名称约定寻找包含 License 的 Secret,如果存在,便通过 Http Client 更新 License。
总结
ElasticSearch 作为有状态的应用,ElasticSearch Operator 除了管理 K8s
资源外,还利用 ES Client,通过保姆式服务完成了生命周期管理。这样的设计虽然巧妙,但是非常依赖 ES Cluster 自身已有的比较完善的自管理能力(比如数据分片的重调度,自发现等)。
如果需要管理的有状态应用不具备如此完善的自管理能力,每次的矫正操作需要多次 requeue 进行 Reconcile 才能完成,势必会使恢复时间变得漫长。对于有状态的应用,恢复的时间(停机的时间)越长,造成的损失越大。也许将实例管理(Pod 管理),和业务管理(应用配置和数据恢复等)分离是个更好的方向。


